
|
|
|
|
 Far Far |
| WinNavigator |
| Frigate |
| Norton
Commander |
| WinNC |
| Dos
Navigator |
| Servant
Salamander |
| Turbo
Browser |
|
|
| Winamp,
Skins, Plugins |
| Необходимые
Утилиты |
| Текстовые
редакторы |
| Юмор |
|
|

|
File managers and best utilites |
Краткая история развития баз данных. Реферат история развития субд
История развития систем управления базами данных
Количество просмотров публикации История развития систем управления базами данных - 698
Важным этапом развития ИС явился переход к использованию централизованных систем управления файлами. Широкое распространение получили индексированные файлы. Файл является простым набором записей (record), которые содержат логически связанные данные. Каждая запись содержит логически связанный набор из одного или нескольких полей (field), каждое из которых представляет некоторую характеристику моделируемого объекта. С точки зрения прикладной программы файл – именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные.
Недостатки файловых систем:
1. Изоляция данных. При изолированных файлах возрастает время доступа к данным и возникают трудности извлечения данных из двух и более файлов.
2. Зависимость от данных. Физическая структура и способ хранения записей файлов данных жестко зафиксированы в коде приложения, что приводит к сложности изменения существующей структуры данных.
3. Несовместимость формата данных. Структура файлов определяется кодом приложения, следовательно, зависит от языка программирования этого приложения. Несовместимость файлов, написанных на различных языках программирования, затрудняет процесс их совместной обработки.
4. Дублирование данных. Из-за децентрализованной работы с данными в файловой системе допускается бесконтрольное дублирование данных, что приводит не только к неэкономному расходованию ресурсов, но и к нарушению целостности данных и, как следствие, противоречивости хранящихся данных.
5. Невозможность многопользовательского режима работы.
Эти недостатки послужили причиной разработки нового подхода к управлению информацией. Разработаны системы управления базами данных (СУБД).
К СУБД первого поколения можно отнести системы, основанные на инвертированных списках, иерархические и сетевые системы управления базами данных.
Инвертированные списки представляют из себясписок таблиц и список индексов, позволяющих осуществлять доступ к данным, хранимым в таблицах.
Общие правила определения целостности в системах на базе инвертированных списков отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу. С помощью индексов осуществляется поиск по вторичному ключу. БД, организованная с помощью инвертированных списков, похожа на реляционную, но с тем различием, что индексы доступны.
В 1968 году появилась первая версия базы данных Information Management System (IMS) фирмы IBM. Применяемая структура, напоминала перевернутое дерево и была названа иерархической структурой.
Другим заметным достижением середины 1960-х годов было появление системы IDS (Integrated Data Store) фирмы General Electric. Развитие этой системы привело к созданию нового типа систем управления базами данных — сетевых СУБД. Сетевая СУБД создавалась для представления более сложных взаимосвязей между данными, чем те, которые можно было моделировать с помощью иерархических структур, а также для формирования стандарта баз данных. В 1971 году для утверждения Национальным институтом стандартизации США (American National Standards Institute — ANSI), группой DBTG был представлен стандарт баз данных, содержаий три компонента:
· Сетевая схема — это логическая организация всей базы данных в целом (с точки зрения АБД), которая включает определение имени базы данных, типа каждой записи и компонентов записей каждого типа.
· Подсхема — это часть базы данных, как она видится пользователями или приложениями.
· Язык управления данными — инструмент для определения характеристики структуры данных, а также для управления ими.
Той же группой DBTG было предложено стандартизировать три языка:
· Язык определения данных для схемы (Data Definition Language — DDL), который позволяет администраторам баз данных ее описать.
· Язык определения данных для подсхемы (также DDL), который позволяет определять в приложениях те части базы данных, доступ к которым будет необходим.
· Язык манипулирования данными (Data Manipulation Language — DML), предназначенный для управления данными.
Несмотря на то что данный отчет официально не был утвержден Национальным институтом стандартизации США (American National Standards Institute — ANSI), большое количество систем было разработано в полном соответствии с этими предложениями группы DBTG.
Всем СУБД первого поколения присущи следующие достоинства:
· Развитые средства управления данными во внешней памяти на низком уровне.
· Возможность построения вручную эффективных прикладных систем.
· Возможность экономии памяти за счёт разделения подобъектов (в сетевых системах).
Всем СУБД первого поколения присущи перечисленные ниже недостатки:
· Даже для выполнения простых запросов с использованием переходов и доступов к определенным записям крайне важно создавать достаточно сложные программы.
· Независимость от данных существует лишь в минимальной степени.
· Отсутствие общепризнанных теоретических основ.
В 1970 году Э. Ф. Кодд (Е. F. Codd), работавший в исследовательской лаборатории корпорации IBM, опубликовал статью о реляционной модели данных, позволявшей устранить недостатки прежних моделей. Вслед за этим появилось множество экспериментальных реляционных СУБД, а первые коммерческие продукты появились в 1970-1980-х годах. Корпорацией IBM, расположенной в городе Сан-Хосе, штат Калифорния, созданной в конце 1970-х годов, был задуман проект с целью доказать практичность реляционной модели, что достигалось посредством реализации предусмотренных ею структур данных и требуемых функциональных возможностей. На базе этого проекта были получены важнейшие результаты.
· Был разработан структурированный язык запросов SQL, который с тех пор стал стандартным языком любых реляционных СУБД.
· В 1980-х годах были созданы различные коммерческие реляционные СУБД — к примеру DB2 или SQL/DS корпорации IBM или Oracle корпорации Oracle Corporation.
Сегодня существует несколько сотен различных реляционных СУБД. В качестве примеров многопользовательских СУБД могут служить система INGRES II фирмы Computer Associates и система Informix фирмы Informix Software, Inc. Примерами реляционных СУБД для персональных компьютеров являются Access и FoxPro фирмы Microsoft, Paradox фирмы Corel Corporation, InterBase и BDE iupMbi Borland, а также R:Base фирмы R:Base Technologies. Реляционные СУБД относятся к СУБД второго поколения.
При этом реляционная модель обладает также некоторыми недостатками, в частности ограниченными возможностями моделирования. Для решения этой проблемы был выполнен большой объём исследовательской работы. В 1976 году Питер Чен) предложил модель "сущность-связь" (Entity-Relationship model — ER-модель), которая в настоящее время стала самой распространенной технологией проектирования баз данных и является основой методологии. В 1979 году Кодд сделал попытку устранить недостатки собственной основополагающей работы и опубликовал расширенную версию реляционной модели — RM/T (1979), затем еще одну версию — RM/V2 (1990). Попытки создания модели данных, позволяющей более точно описывать реальный мир, неформально называют семантическим моделированием данных (semantic data modeling).
В ответ на все возрастающую сложность приложений баз данных появились две новые системы: объектно-ориентированные СУБД, или ООСУБД (Object-Driented DBMS — OODBMS), и объектно-реляционные СУБД, или ОРСУБД Object-Relational DBMS — ORDBMS). При этом в отличие от предыдущих моделей действительная структура этих моделей не совсем ясна. Попытки реализации подобных моделей представляют из себяСУБД третьего поколения.
referatwork.ru
Краткая история развития баз данных
Историю развития баз данных можно разделить на четыре периода.
1. Период становления – начало 60-х - начало 70-х гг. В этот период появляется сам термин «база данных» и создается несколько первоначальных систем. Основой появления баз данных явилось предложение конца 50-х годов использовать файлы для хранения исходных данных. Основное требование к таким файловым системам – быть совместно используемым хранилищем данных. В последующем стало очевидным, что совместно используемые данные, должны обладать специфическими свойствами, в частности: независимость данных, отсутствие дублирования и противоречивости, контроль прав доступа к данным, эффективная техника доступа к данным, а также многие другие.
Осознание этих фактов, а также появление больших компьютеров с магнитными дисками в качестве носителей данных привело к появлению в середине 60-х гг. первых систем управления базами данных, из которых наиболее развитой оказалась система IMS фирмы IMB, которая поддерживала иерархическую структуру данных. Бахман в 1963 г. разработал первую промышленную систему баз данных IDS. СистемаIDSподдерживала сетевую организацию данных на магнитных носителях.
Ассоциация CODASYL, являющаяся органом, разработавшим язык программирования Кобол, в 1967 г. организовала рабочую группу по базам данных. Эта группа обобщила языковые спецификации систем баз данных и в 1969 и 1971 гг. издала соответствующие отчеты, которые по наименованию рабочей группы (DataBaseTaskGroup) получили названиеDBTG69,DBTG71. Основой избранного Рабочей группой подхода послужила сетевая структура данных и способы навигации по ней, разработанные в системе IDS, однако сетевая модель данных в отчетах DBTG получила существенное развитие и обоснование.
Типичным представителем системы, поддерживающей предложения DBTGCODASYLявилась Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем.
В этот же период четко выкристаллизовались два подхода относительно проблемы замкнутости систем баз данных. Системы замкнутого типахарактеризуются тем, что они не содержат в своем составе традиционных языков программирования, а имеют непроцедурные языки запросов. Основной целью в данном случае является создание системы, с применением которой мог бы справиться не специалист по программированию К таким системам относились TDMS иUL/1.
Системы с включаемыми языкамипомимо собственно языков манипулирования базами данных предоставляют также языковые и инструментальные средства разработки приложений, с использованием существующих языков программирования. Этот принцип, в частности, исповедовался DBTG.
В конце данного периода появился термин информационно-управляющая система(MIS). В то время подMISпонималась система баз данных, ориентированная на поиск данных и обеспечивающая возможность работы с удаленного терминала.
Период развития – 70-е годы. Концепция баз данных широко распространяется благодаря повышению характеристик аппаратного обеспечения компьютеров. Идет успешное внедрение систем, поддерживающих иерархическую и сетевую структуры данных.
Все этот период продолжалась работа DBTG CODASYL. Была специфицирована система языков для баз данных CODASYL, которая включила следующие группы языковых спецификаций:
Язык описания данных ЯОД (Data Definition Language - DDL). Представляет собой описание концептуальной схемы в терминах сетевой структуры данных.
Средства базы данных языка Кобол. Представляет собой средства обеспечения интерфейса языка Кобол с базой данных, описанной в DDL. В Кобол включены средства языка манипулирования данными.
Средства базы данных языка Фортран. Представляет собой средства обеспечения интерфейса языка Фортран с базой данных, описанной в DDL. В Кобол включены средства языка манипулирования данными.
Средства конечного пользователя. Определяет интерфейс пользователя случае, когда такой пользователь управляет базой данных, описанной в DDL.
Язык описания хранения данных ЯОХД (Data Stored Definition Language - DSDL). Представляет собой язык, который отображает концептуальную схему, описанную в DDL, во внутреннюю схему.
В 1975 г. появился отчет рабочей группы ANSI/X3/SPARCАмериканского Национального Института Стандартов, который явился значительной вехой в развитии проблематики баз данных. Перед группой была поставлена задача исследовать, в какой мере целесообразно ставить вопрос о стандартизации баз данных и СУБД и что именно может быть подвержено стандартизации. Группа пришла к выводу, что если и ставить вопрос о стандартизации, то только относительно интерфейсов, которые могут существовать между различными компонентами СУБД, сами программные компоненты ни в коем случае подвергаться стандартизации не могут. В связи с этим они направили свои последующие усилия на выявление таких интерфейсов и, в конце концов, пришли к формулировке трехуровневой архитектуре баз данных, которая стала классической и не потеряла свою актуальность до сих пор.
Однако этот период в большей мере характеризуется появлением реляционной модели данных, предложенной в 1970 г. сотрудником института фирмы ИБМ в Сан-Хосе Э.Ф. Коддом, всесторонними исследованиями теоретических и прикладных вопросов этой модели, разработкой экспериментальных реляционных СУБД. Теоретические исследования привели, в конце концов, к созданию формальной теории баз данных, которая до этого носила описательный характер. На протяжении многих лет многие ведущие формы проводили экспериментальные исследования по созданию прототипов реляционных СУБД, повышению их эффективности и функциональности. В конце 70-х гг. появляются первые промышленные реляционные СУБД.
Период зрелости – 80-е годы. Реляционная модель получила полное теоретическое обоснование. Разработаны крупные реляционные СУБД Oracle, Informix, и другие. Промышленные реляционные системы получают широкое распространение во всех сферах человеческой деятельности. Реляционные системы практически вытеснили с мирового рынка ранние СУБД иерархического и сетевого типа.
Дальнейшее развитие реляционных СУБД шло в следующих направлениях:
Удобство применения. Появление персональных компьютеров сделал принципиальным вопрос удобства использования программ, что также относилось и к СУБД. На протяжении всего этого периода интенсивно развивается внешний интерфейс взаимодействия пользователей с базами данных.
Многоплановость. Изначально базы данных разрабатывались для хранения и обработки символьной информации и традиционно использовались в таких сферах, как обработка экономической информации, статистика, банковское дело, системы резервирования, информационные системы различного направления. Появление спроса к базам данных в нетрадиционных сферах их применения, системы автоматизации проектирования, издательское дело и другие, потребовали хранения в базах данных и обработки изображений, звуков, полнотекстовой информации.
Этот период также характеризуется теоретическими и экспериментальными исследованиями в области баз знаний. Разрабатываются многочисленные экспертные системы, использующие базы знаний. В подавляющем большинстве случаев базы знаний разрабатываются на основе реляционных СУБД.
Постреляционный период – с начало 90-х гг. В этот период начались проводиться интенсивные исследования по дедуктивным и объектно-ориентированным базам данных, а также разработка исследовательских прототипов таких систем.
Особое место в развитии проблематики объектно-ориентированных СУБД занимает деятельность группы по управлению объектными базами данных ODMG(ObjectDataManagementGroup), - неприбыльным консорциумом производителей объектных баз данных и других организаций, заинтересованных в выработке стандартов по хранению объектов в базах данных.ODMGбыла создана в 1991 г. В 1993 г. группа выпустила свой первый стандарт –ODMG-93. В 1995 г. был опубликован усовершенствованный вариант этого стандарта.
В связи с развитием Интернет-технологий прикладываются большие усилия по внедрению баз данных в Интернет. Возникают различные подходы по включению СУБД с их базами данных во всемирную паутину, начиная от простейших «публикаций» баз данных в Интернет и заканчивая разработкой web-серверов баз данных, которые в состоянии предоставлять весь спектр услуг пользователям Интернета по использованию баз данных на сервере.
Наконец, интенсивно развиваются исследования и разработки по представлению и манипулированию структурами данных в Интернет.
Базы данных и знаний 9
studfiles.net
История развития СУБД | Генерим!
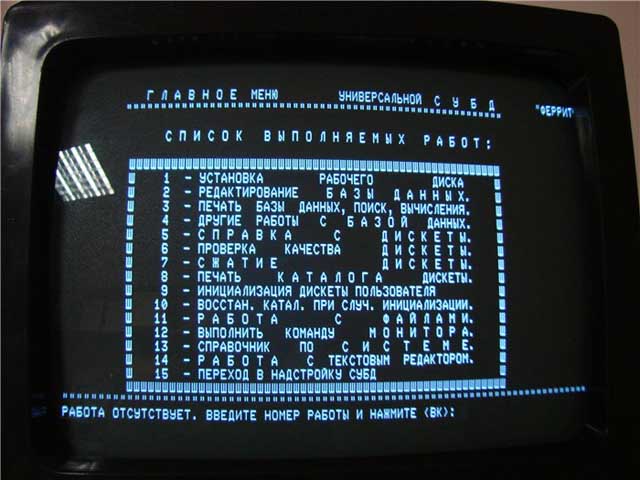 История СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД – система IMS фирмы IBM.
История СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД – система IMS фирмы IBM.
Первый этап становления СУБД относится к 70-м годам XX века. В 1975 году появился первый стандарт СУБД, разработанный ассоциацией по языкам систем обработки данных – Conference of Data System Language (CODASYL). Этот стандарт определил ряд фундаментальных понятий в теории систем баз данных, которые до сих пор являются основополагающими для сетевой модели данных.
В 1981 году Э.Ф.Кодд создал реляционную модель данных и применил к ней операции реляционной алгебры. В истории развития баз данных можно выделить следующие этапы:
- Файлы и файловые системы;
- Базы данных на больших ЭВМ. Первые СУБД;
- Эпоха персональных компьютеров. Настольные СУБД;
- Распределенные базы данных.
Нет жестких временных ограничений между этапами развития баз данных, они плавно переходят один в другой и даже существуют параллельно.
В первых компьютерах использовались два вида внешних устройств:
— магнитные ленты;
— магнитные барабаны.
Емкость магнитных лент была достаточно велика. Устройства для чтения-записи магнитных лент обеспечивали последовательный доступ к данным. Для чтения информации, которая находилась в середине или конце магнитной ленты, необходимо было сначала прочитать весь предыдущий участок. Следствием этого являлось чрезвычайно низкая производительность операций ввода-вывода данных во внешнюю память.
Второй этап (80-е года XX века) развития баз данных связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ, разных моделях фирмы Hewlett Packard.
Базы данных хранились во внешней памяти центральной ЭВМ. Пользователями баз данных были задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, оперативной памятью, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ.
Третий этап приходится на 90-е года XX века(«этап персонализации»). На этом этапе появились программы, которые назывались системами управления базами данных и позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения данных, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную.
Постоянное снижение цен на персональные компьютеры сделало их доступными не только для организаций и фирм, но и для отдельных пользователей. Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов.
Наличие на рынке большого числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных.
Особенности этого этапа следующие:
1. Стандартизация высокоуровневых языков манипулирования данными (разработка и внедрение стандарта SQL92 во все СУБД).
2. СУБД были рассчитаны на создание БД в основном с монопольным доступом. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
3. Большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с БД как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования.
4. В настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
5. При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц.
6. В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
7. Сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286. В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства очень широко использовавшиеся до недавнего времени СУБД Dbase (DbaseIII+, DbaseIV), FoxPro, Clipper, Paradox.
После процесса «персонализации» начался обратный процесс — интеграция. Множится количество локальных сетей, все больше информации передается между компьютерами, остро встает задача согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически друг с другом связанных, возникают задачи, связанные с параллельной обработкой транзакций — последовательностей операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. Успешное решение этих задач приводит к появлению распределенных баз данных, сохраняющих все преимущества настольных СУБД и в то же время позволяющих организовать параллельную обработку информации и поддержку целостности БД.
Именно к этому этапу можно отнести начало работ, связанных с концепцией объектно-ориентированных БД — ООБД. Представителями СУБД, относящимся ко второму этапу, можно считать MS Access 2000 и все современные серверы баз данных Oracle7.3, Oracle8.4 MS SQL6.5, MS SQL7.0, System 10, System 11, Informix, DB2, SQL Base.
Однако беспрецедентные объемы данных заставляют разработчиков и бизнес использовать альтернативы реляционных баз данных, работающих более тридцати лет. В совокупности все эти технологии известны как «NoSQL базы данных». Термин «NoSQL» был придуман Эриком Эвансом (Eric Evan / Racker).
Подготовлено по материалам:
- «История баз данных» http://www.intuit.ru/department/database/dbmdi/1/
- Эрик Спирли. Корпоративные хранилища данных. Москва: «Вильямс», 2001. 396с.
generim.ru

|
|
..:::Счетчики:::.. |
|
|
|
|
|
|
|
|