Действующие в настоящее время стратегические планы и программы развития РЖД как одной из ключевых инфраструктурных отраслей национальной экономики предусматривают ускоренные темпы обновления основных фондов, модернизацию и развитие инфраструктурных объектов, внедрение более прогрессивных методов и средств управления на всех уровнях организационной иерархии.
Достижение этих целей связано с широким внедрением современных информационных и интеллектуальных технологий, которые призваны обеспечить непрерывный мониторинг действующих производственных мощностей и процессов, проводить диагностику и прогнозирование состояния используемых активов для оценки остаточного ресурса, организацию на этой основе своевременного технического обслуживания, планирования и проведения ремонтных мероприятий с учетом их реальных потребностей.
Анализ используемых в настоящее время технологий, методов и средств мониторинга, диагностики и прогнозирования не всегда оказываются эффективными из-за большой их трудоемкости, несвязности и локальности способов обслуживания, несогласованности во времени. Актуальным в этой связи становится переход к интеллектуализированным системам, позволяющим в реальном масштабе времени осуществить мониторинг действующих процессов, диагностировать и оценивать текущее состояние, остаточный ресурс, принятие решения и эффективное управление.
Современные системы поддержки принятия решения (СППР), возникшие как естественное развитие и продолжение управленческих информационных систем и систем управления базами данных, представляют собой системы, максимально приспособленные к решению задач повседневной управленческой деятельности, являются инструментом, призванным оказать помощь лицам, принимающим решения (ЛПР). С помощью СППР могут решаться неструктурированные и слабоструктурированные многокритериальные задачи. СППР, как правило, являются результатом мультидисциплинарного исследования, включающего теории баз данных, искусственного интеллекта, интерактивных компьютерных систем, методов имитационного моделирования.
В настоящее время нет общепринятого определения СППР, поскольку конструкция СППР существенно зависит от вида задач, для решения которых она разрабатывается, от доступных данных, информации и знаний, а также от пользователей системы. Можно привести, тем не менее, некоторые элементы и характеристики, общепризнанные, как части СППР: СППР - в большинстве случаев – это интерактивная автоматизированная система, которая помогает пользователю, лицу принимающему решение, использовать данные и модели для идентификации и решения задач и принятия решений. Система должна обладать возможностью работать с интерактивными запросами с достаточно простым для изучения языком запросов. СППР обладает следующими четырьмя основными характеристиками:
1) СППР использует и данные, и модели;
2) СППР предназначены для помощи менеджерам в принятии решений для слабоструктурированных и неструктурированных задач;
3) Они поддерживают, а не заменяют, выработку решений менеджерами;
4) Цель СППР – улучшение эффективности решений.
Идеальная СППР:
1) оперирует со слабоструктурированными решениями;
2) предназначена для ЛПР различного уровня;
3) может быть адаптирована для группового и индивидуального использования;
4) поддерживает как взаимозависимые, так и последовательные решения;
5) поддерживает 3 фазы процесса решения: интеллектуальную часть, проектирование и выбор;
6) поддерживает разнообразные стили и методы решения, что может быть полезно при решении задачи группой ЛПР;
7) является гибкой и адаптируется к изменениям как
организации, так и ее окружения;
8) проста в использовании и модификации;
9) улучшает эффективность процесса принятия решений;
10) позволяет человеку управлять процессом принятия решений с помощью компьютера, а не наоборот;
11) поддерживает эволюционное использование и легко адаптируется к изменяющимся требованиям;
12) может быть легко построена, если может быть сформулирована логика конструкции СППР;
13) поддерживает моделирование;
14) позволяет использовать знания.
Стремление к повышению информационного и интеллектуального уровня действующих моделей систем управления связано с созданием и широким внедрением системы поддержки принятия решений в реальном масштабе времени (СППР РМВ) в оперативно-диспетчерское управление (ОДУ). Такие системы основаны на современных информационных и интеллектуальных технологиях, базах знаний и процедурах поиска решений на знаниях, а также моделях и инструментальных средствах представления и обработки данных и знаний, которым свойственны неопределенность и риск.
Опыт эксплуатации технологического оборудования и технологических процессов в энергетике показывает, что большинство задач оперативно-диспетчерское управление относится к классу слабоструктурированных и плохоформализуемых задач, характерными особенностями которых являются :
- невозможность получения полной и объективной информации для принятия адекватных решений и обусловленная этим обстоятельством необходимость привлечения неформальной (субъективной, эвристической) информации;
- наличие неопределенности в исходных данных, а также присутствие неоднозначности (многовариантности) процесса поиска решений;
- необходимость корректировки и введения дополнительной информации в процесс поиска решений, интерактивный (человеко-машинный, диалоговый) характер логического вывода решений;
- необходимость выработки и обоснования искомых решений проблемы в условиях жестких временных ограничений, которые определяются ходом управляемых процессов.
Эти системообразующие факторы энергетических объектов заставляют отказаться от традиционных алгоритмических методов и моделей принятия решений и управления и перейти к созданию и внедрению более эффективных - интеллектуальных технологий (технологий экспертных систем). Именно такие технологии позволяют обеспечить совместное и согласованное решение таких традиционных задач оперативно-диспетчерское управление, как непрерывный мониторинг, техническая диагностика, прогнозирование изменения технического состояния объекта во времени, оперативное вмешательство в ход процессов, а также планирование необходимых ремонтных и восстановительных мероприятий.
Присущая интерактивным системам, функционирующим в реальном масштабе, времени, организованная творческая технология существенно снижает степень влияния рисков, повышает ценность оперативных решений и оперативного вмешательства, делает прозрачными параметры дальнейшего хода контролируемых процессов.
|
|
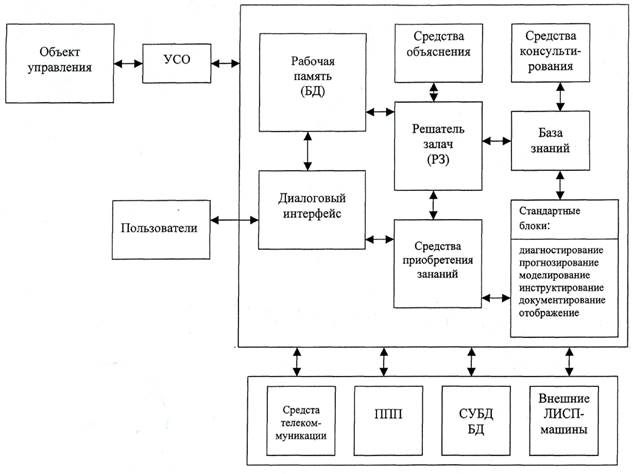
Рис.1
Как следует из рисунка, она должна через устройство связи с объектом (УСО) поддерживать непрерывную и двустороннюю связь с объектом мониторинга и управления (генерирующее оборудование). Оперативные данные об объекте, а также данные, характеризующие необходимое воздействие на него со стороны системы, образуют рабочую память системы или ее оперативную базу данных (БД). Центральным звеном СППР является решатель задач (РЗ), который в диалоге с персоналом (лицами, принимающими решение) обеспечивает идентификацию ситуации, логический вывод решений, объяснение и обоснование этих решений, взаимодействие с базами данных и знаний, а также использует традиционные (внешние) средства моделирования, алгоритмизации и программирования. Важной функцией решателя задач является также выполнение стандартных функции по технической диагностике, прогнозированию, моделированию, консультированию, документированию и отображению информации.
Благодаря непрерывной связи между системой и объектом управления осуществляется непрерывный мониторинг его параметров и как можно более раннее обнаружение неблагоприятных тенденций и отклонений в его состоянии. Соответствующие информационно-аналитические компоненты системы осуществляют сбор, хранение и обработку оперативной информации о состоянии объекта и происходящих в нем процессах. Она необходима для принятия оперативных решений, при отклонении текущих значений контролируемых параметров от установленных их номинальных (или рабочих) значений.
Одним из ключевых концептуальных положений создания производственных систем реального времени является совместное и согласованное решение следующих трех ключевых системных задач: техническая диагностика, прогнозирование, принятие решений и управление. Несмотря на относительную автономность, эти задачи находятся в «системном единстве».
Использование различных типов блочных моделей и программ в математическом обеспечении задачи прогнозирования позволяет достичь приемлемого темпа моделирования, значительно превышающего реальный темп протекания контролируемого технологического процесса. Комбинированная с задачами диагностики и прогнозирования, задача моделирования поведения объекта выступает как источник данных о состоянии объекта на этапах тестирования системы и управления объектом.
moluch.ru
Интеллектуальные системы поддержки принятия решений
Суслова Екатерина Владимировна, магистрант
Национальный исследовательский Мордовский государственный университет имени Н. П. Огарева
Любое предприятие осуществляет свою деятельность в условиях риска и неопределенности, поэтому перед ним постоянно стоит проблема выживания и обеспечения непрерывности функционирования и развития [1]. Анализ функционирования крупных предприятий и управление ими составляет основное содержание работы управленцев, аналитиков, специалистов в области обработки информации [2, с. 74–76]. Чтобы решить эту проблему руководителям приходится принимать управленческие решения по выбору направления развития предприятия, по сохранению и увеличению своей позиции на рынке и рыночной доли, по предотвращению потерь и снижению издержек, а также по поддержанию и повышению конкурентоспособности. Обоснованность и профессиональный уровень принимаемых решений определяет, в конце концов, эффективность деятельности предприятия.
В современных условиях всё возрастающую роль играет информация. Однако необходимость учета при принятии управленческих решений большого количества экономических, политических, социальных, правовых факторов существенно усложняет процесс выбора правильного варианта решения. Как правило, это связано со сложностями, возникающими в процессе сбора актуальной, достоверной и полной информации по интересующему вопросу. Стремительное увеличение объемов поступающей и перерабатываемой информации приводит к значительным изменениям в способах и методах анализа информации и требует не только автоматизации процесса обработки и изучения данных, но и интеллектуализации информационных и организационных процессов, построения и внедрения эффективных методов и интеллектуальных технологий поддержки принятия решений (ППР).
За последние десятилетия информационные технологии достигли высокого уровня развития. В связи с этим большинство развивающихся компаний используют автоматизированные средства, позволяющие эффективно хранить, обрабатывать и распределять накопленные данные [3]. Современные системы поддержки принятия решений (СППР) появились благодаря развитию управленческих информационных систем и систем управления базами данных (СУБД) и представляют собой системы, приспособленные к решению текущих задач, возникающих в управленческой деятельности. Это мощный инструмент, позволяющий помочь лицам, принимающим решения (ЛПР), решить сложные неструктурированные задачи. Как правило, системы поддержки принятия решений являются результатом мультидисциплинарного исследования, которое включает в себя теории баз данных, методов имитационного моделирования, искусственного интеллекта, нейронных сетей, ситуационного анализа и интерактивных компьютерных систем. В настоящее время нет единого общепринятого определения СППР, т. к. строение системы напрямую зависит от тех задач, для решения которых она используется, а также от доступных знаний, данных и информации, на основе которых принимаются решения.
Для решения слабоструктурированных или неструктурированных управленческих задач, с которыми достаточно сложно справиться естественному интеллекту, возникает необходимость в создании и использовании систем искусственного интеллекта для принятия решений, т. е. интегрированных интеллектуальных систем управления, в состав основных компонентов которых включаются базы данных и знаний, блок решения и логического вывода, хранилище моделей и т. п. Создание подобных систем стало возможным благодаря развитию и достижениям интеллектуального управления, основанным на разработках в области искусственного интеллекта, инженерии знаний, обработки данных и математического моделирования.
Попытки наделить компьютерную технику интеллектуальными способностями более высокого уровня (вероятностными методами рассуждения, логикой, индуктивным выводом, доказательством по аналогии и проч.) до сих пор не дали ощутимого результата. К известным методам и способам автоматизации решения задач управления путем применения интеллектуальных функций относятся:
использование нейронных сетей и нейрокомпьютеров на уровне распознавания (классификации) и обобщения объектов и ситуаций;
В своих работах американский нейрофизиолог Френсис Розенблатт предложил свою модель нейронной сети, которая должна применяться для задачи автоматической классификации, состоящей в общем случае в разделении пространства признаков между заданным количеством классов.
Эти системы (и подобные им) получили название персептроновисостояли в основном из одного слоя искусственных нейронов, соединенных с помощью весовых коэффициентов с множеством входов.
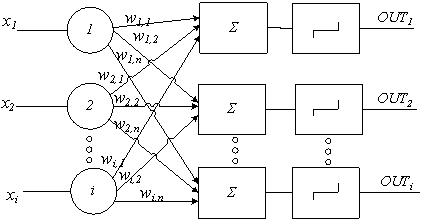
Рис. 1. Однослойный персептрон
Начало современному математическому моделированию нейронных вычислений было положено работами Хопфилда в 1982 году, в которых была сформулирована математическая модель ассоциативной памяти на нейронной сети с использованием правила Хеббиана для программирования сети (рисунок 2). Введенная в эту модель Хопфилдом функция вычислительной энергии нейронной сети стала одним из новых путей развития искусственных нейронных сетей.
Недостатком модели Хопфилда является их тенденция стабилизироваться в локальном, а не глобальном минимуме функции энергии, поэтому эволюционным развитием модели для решения комбинаторных оптимизационных задач и задач искусственного интеллекта является машина Больцмана.
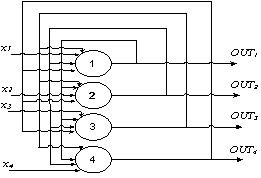
Рис. 2. Сеть Хопфилда из 4 нейронов
Самоорганизующаяся карта признаков (сеть SOFM — Self-Organizing Feature Map), разработанная Кохоненом в 80-х гг., имеет набор входных элементов, число которых соответствует размерности учебных векторов, и набор выходных элементов, которые служат в качестве прототипов. Основная архитектура сети SOFM приведена на рисунке 3
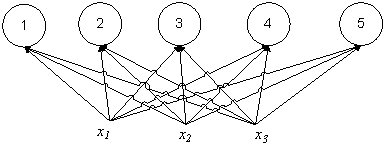
Рис. 3. Сеть Кохонена с тремя входными и пятью кластерными элементами, каждый элемент входного слоя связан с каждым элементом кластерного слоя
В конце 80-х годов были разработаны сети встречного распространения, которые превосходят возможности однослойных сетей. Время обучения в них, по сравнению сетями с обратным распространением ошибки, может уменьшаться в сто раз. Обратное распространение может давать решение в тех приложениях, где долгая обучающая процедура невозможна. Во встречном распространении объединены два хорошо известных алгоритма: самоорганизующаяся карта Кохонена и звезда Гроссберга. Их объединение ведет к свойствам, которых нет ни у одного из них в отдельности [4].
Методы, которые подобно встречному распространению, объединяют различные сетевые парадигмы как строительные блоки, могут привести к сетям, более близким к мозгу по архитектуре, чем любые другие однородные структуры. Похоже, что в мозгу именно каскадные соединения модулей различной специализации позволяют выполнять требуемые вычисления.
Таким образом, можно сделать вывод о том, что для полного осуществления интеллектуальных способностей, связанных с анализом, прогнозированием, обобщением исходной информации по сложной управленческой проблеме и, в конечном итоге, принятии верного решения современные и будущие интеллектуальные системы поддержки принятия решений и интеллектуальные системы учета должны быть реализованы с использованием новейших прогрессивных технологий, которые основаны на динамических моделях данных, способных адаптироваться к конкретной ситуации и задаче, концепциях распределенного искусственного интеллекта, параллельной обработки огромных объемов данных в процессе решения, а также методов правдоподобного вывода результатов. Поэтому одним из наиболее перспективных путей построения интеллектуальных систем поддержки принятия решений, систем интеллектуального анализа данных, систем управления и прогнозирования является использование современные научные разработки в теории и практике нейронных сетей, нечёткие модели и методы многокритериального выбора и нечёткого логического вывода.
Литература:Основные термины (генерируются автоматически): поддержки принятия решений, искусственного интеллекта, нейронных сетей, системы поддержки принятия, нейронной сети, систем управления, интеллектуальных систем, автоматизации решения задач, задач искусственного интеллекта, логического вывода, систем искусственного интеллекта, интеллектуальных систем управления, правильного варианта решения, интеллектуальные системы, распределенного искусственного интеллекта, искусственных нейронных сетей, принятии верного решения, использование нейронных сетей, интеллектуальных систем поддержки, неструктурированных управленческих задач.
moluch.ru
ИНТЕЛЛЕКТУАЛЬНЫЕ СИСТЕМЫ ПОДДЕРЖКИ ПРИНЯТИЯРЕШЕНИЯМ.С. ИгнатовНаучный руководитель — д.т.н., профессор О.Ф. НемолочновПроблематика проецирования данных и доступа к ним для ОЬЛР анализа. Проектирование и разработка уровней агрегирования и обработки данных. Использование распределенных вычислительных систем для обработки данных на различных уровнях. Акцентирование необходимости развития систем автоматической нормализации хранилищ данных.ВведениеИстория развития систем управления базами данных (СУБД) тесно связана с совершенствованием подходов к решению задач хранения данных и управления транзакциями. Развитый механизм управления транзакциями в современных СУБД сделал их основным средством построения ОЬТР-систем (систем онлайновой обработки транзакций), основной задачей которых является обеспечение выполнения операций с БД. Современные ОЬТР-системы позволяют совершать большое количество параллельных изменений, а также предоставляют возможность одновременного обращения множества пользователей к одним и тем же данным для чтения, редактирования и удаления.Тем не менее, с развитием структур данных и увеличения объема информации в БД, а также повышением требований к уровню, глубине и качеству анализа стало ясным, что ОЬТР-системы уже не могут эффективно решать возлагаемые на них задачи. Эти системы достаточно успешно решают задачи сбора, хранения и поиска информации, но они не удовлетворяют требованиям, предъявляемым к современным системам поддержки принятия решения (СППР). Основной причиной неудачи развития ОЬТР-систем послужило противоречие требований к ОЬТР и СППР. Причина лежит даже не в противоречии требований, предъявленных к ОЬТР и СППР, а в эволюции требований к самому анализу данных, т. е. что мы хотим получить в ответ от системы.Несмотря на развитие ОЬТР-систем, в СППР узким местом является как раз обращение к БД, особенно при удалении и изменении данных. Поэтому в настоящее время при разработке СППР огромное внимание уделяется проектированию БД в зависимости от объема и структуры данных, а также предполагаемых задач по их анализу. Порой изначально неверно спроектированная архитектура БД приводит к неудачному завершению всего проекта.Обзор средствДля построения СППР существует множество средств, направленных на упрощение структуры СППР, увеличения производительности и надежности системы. Две основные группы средств, применяемые при реализации, — хранилища данных (ХД) и набор аналитических инструментов. ХД предоставляет собой единую среду хранения корпоративных данных, организованных в структурах и оптимизированных для выполнения аналитических операций. Аналитические средства позволяют конечному пользователю, не имеющему специальных знаний в области информационных технологий, осуществлять поиск, отбор и обработку необходимых данных, а также представляют эти данные в терминах предметной области. Для пользователей различной квалификации СППР располагают различными типами интерфейсов доступа к своим сервисам.Концепция хранилищ данныхНа данный момент существует ряд концептуальных подходов, направленных на снижение нагрузки на БД и увеличения скорости анализа данных. Один из таких под-ходов, заключающийся в разделении данных по разным БД в зависимости от выполняемых над этими данными операциями, получил название «Хранилище данных» (ХД). Оперативные и часто изменяющиеся данные в этом случае следует хранить в OLTP БД, а данные, предназначенные для глубокого полноценного анализа, — в другой БД. При этом ввиду того, что при анализе выполняются только операции чтения данных и отсутствуют транзакционные задержки, связанные с ожиданием завершения операций записи и изменения данных, скорость анализа существенно возрастает.Как правило, наиболее удобным способом представления информации для человека является отображение зависимости между различными рассматриваемыми параметрами. Часто возникает потребность в построении зависимостей между большим числом различных параметров, но реляционная БД не удовлетворяет таким требованиям. Такая модель БД, по словам Е. Кодда, «не способна объединять, просматривать и анализировать данные с точки зрения множественности измерений» [3]. Таким образом, было предложено построение многомерной модели данных в виде так называемого «гиперкуба». При построении гиперкуба возникает проблема актуализации всего массива данных в момент добавления новых данных в ХД. Впрочем, как и проектирование БД, проектирование структуры гиперкуба и его физическая реализация влияют как на скорость доступа к данным и скорость их анализа, так и на успешность всего проекта в целом.По сути, принято создавать гиперкуб, содержащий только агрегированные данные, и лишь при необходимости получения детальных данных выполнять операцию агрегации (Drill Down). При этом следует внимательно выбирать между большим количеством измерений куба и высокой степенью агрегированности данных, так как в первом случае мы получаем дублирование данных, а во втором — набор практических бесполезных данных, требующих извлечения из хранилища, что снижает производительность системы. В случае наличия в структуре слабо связанных или не связанных между собой данных существует возможность снижения нагрузки на ХД путем разнесения таких данных по различным физическим хранилищам, что приведет к минимизации объема обрабатываемых данных и повышению быстродействия ХД в целом. Например, ХД предприятия можно разделить на физические хранилища, содержащие данные не взаимодействующих или мало взаимодействующих отделов предприятия.По Кодду, многомерное концептуальное представление (multi-dimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так, измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения «предприятие — подразделение — отдел -служащий». Измерение Время может даже включать два направления консолидации -«год — квартал — месяц — день» и «неделя — день», поскольку счет времени по месяцам и по неделям несовместим.Кодд определил 12 правил, которым должен удовлетворять программный продукт класса OLAP (online analytical processing — аналитическая обработка в реальном времени) (таблица 1).Набор этих требований, послуживших фактическим определением OLAP, следует рассматривать как рекомендательный, а конкретные продукты оценивать по степени приближения к идеально полному соответствию всем требованиям.№ Правило Описание1. Многомерное концептуальное представление данных (MultiDimensional Conceptual View) Концептуальное представление модели данных в продукте OLAP должно быть многомерным по своей природе, т. е. позволять аналитикам выполнять интуитивные операции «анализа вдоль и поперек» («slice and dice»), вращения (rotate) и размещения (pivot) направлений консолидации.2. Прозрачность (Transparency) Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда берутся.3. Доступность (Accessibility) Аналитик должен иметь возможность выполнять анализ в рамках общей концептуальной схемы, но при этом данные могут оставаться под управлением оставшихся от старого наследства СУБД, будучи при этом привязанными к общей аналитической модели. То есть инструментарий OLAP должен накладывать свою логическую схему на физические массивы данных, выполняя все преобразования, требующиеся для обеспечения единого, согласованного и целостного взгляда пользователя на информацию.4. Устойчивая производительность (Consistent Reporting Performance) С увеличением числа измерений и размеров базы данных аналитики не должны столкнуться с каким бы то ни было уменьшением производительности. Устойчивая производительность необходима для поддержания простоты использования и свободы от усложнений, которые требуются для доведения OLAP до конечного пользователя.5. Клиент — серверная архитектура (ClientServer Architecture) Большая часть данных, требующих оперативной аналитической обработки, хранится в мэйнфреймовых системах, а извлекается с персональных компьютеров. Поэтому одним из требований является способность продуктов OLAP работать в среде клиент-сервер. Серверный компонент инструмента OLAP должен быть достаточно интеллекту аль-ным и обладать способностью, строить общую концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных баз данных для обеспечения эффекта прозрачности.6. Равноправие измерений (Generic Dimensionality) Все измерения данных должны быть равноправны. Дополнительные характеристики могут быть предоставлены отдельным измерениям, но поскольку все они симметричны, данная дополнительная функциональность может быть предоставлена любому измерению. Базовая структура данных, формулы и форматы отчетов не должны опираться на какое-то одно измерение.7. Динамическая обработка разреженных матриц (Dynamic Sparse Matrix Handling) Инструмент OLAP должен обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной для моделей, имеющих разное число измерений и различную разреженность данных.8. Поддержка многопользовательского режима (Multi-User Support) Зачастую несколько аналитиков имеют необходимость работать одновременно с одной аналитической моделью или создавать различные модели на основе одних корпоративных данных. Инструмент OLAP должен предоставлять им конкурентный доступ, обеспечивать целостность и защиту данных.9. Неограниченная поддержка кросс-мерных операций (Unrestricted Cross-dimensional Operations) Вычисления и манипуляция данными по любому числу измерений не должны запрещать или ограничивать любые отношения между ячейками данных. Преобразования, требующие произвольного определения, должны задаваться на функционально полном формульном языке.10. Интуитивное манипулирование данными (Intuitive Data Manipulation) Переориентация направлений консолидации, детализация данных в колонках и строках, агрегация и другие манипуляции, свойственные структуре иерархии направлений консолидации, должны выполняться в максимально удобном, естественном и комфортном пользовательском интерфейсе.11. Гибкий механизм генерации отчетов (Flexible Reporting) Должны поддерживаться различные способы визуализации данных, т. е. отчеты должны представляться в любой возможной ориентации.12. Неограниченное количество измерений и уровней агрегации (Unlimited Dimensions and Aggregation Levels) Настоятельно рекомендуется допущение в каждом серьезном OLAP-инструменте как минимум пятнадцати, а лучше двадцати, измерений в аналитической модели. Более того, каждое из этих измерений должно допускать практически неограниченное количество определенных пользователем уровней агрегации по любому направлению консолидации.Таблица 1. Правила оценки программных продуктов класса OLAPИнтеллектуальный анализ данныхВ нынешнее время активно используется направление в аналитических технологиях обработки данных — Data Mining, что переводится как «добыча» или «раскопка данных». Нередко рядом с Data Mining встречаются слова «обнаружение знаний в базах данных» (knowledge discovery in databases) и «интеллектуальный анализ данных».Цель Data Mining состоит в выявлении скрытых правил и закономерностей в наборах данных. Дело в том, что человеческий разум сам по себе не приспособлен для восприятия больших массивов разнородной информации. Человек к тому же не способен улавливать более двух-трех взаимосвязей даже в небольших выборках. Но и традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, также нередко пасует при решении задач из реальной сложной жизни. Она оперирует усредненными характеристиками выборки, которые часто являются фиктивными величинами. Поэтому методы математической статистики оказываются полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining).Современные технологии Data Mining (discovery-driven data mining) обрабатывают информацию с целью автоматического поиска шаблонов, характерных для каких-либо фрагментов неоднородных многомерных данных. В отличие от оперативной аналити-ческой обработки данных (OLAP) в Data Mining бремя формулировки гипотез и выявления необычных шаблонов переложено с человека на компьютер.Типы выявляемых закономерностейВыделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining.• Ассоциация имеет место в том случае, если несколько событий связаны друг с другом.• Если существует цепочка связанных во времени событий, то говорят о последовательности.• С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.• Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.• Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить математическую модель и найти шаблоны, адекватно отражающие эту динамику, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.ЗаключениеОбобщая вышеизложенный материал, хочется отметить масштабность и широту текущих исследований вопросов организации хранения и обработки данных, а также большое количество используемых для решения этих задач технологий, каждая из которых даже сама по себе требует существенных ресурсов для изучения и развития. Если методологии и технологии решения задач, связанных с выявлением закономерностей в больших объемах данных, в настоящее время развиваются стремительно, то таким вопросам, как заблаговременное проектирование оптимальных структур ХД и гиперкуба и распределение физического расположения данных, а также поддержка актуальности и оптимальности их состояния и структуры в условиях быстро меняющейся внешней среды, уделяется недостаточно внимания. Однако значимость этих вопросов в скором времени станет существенной в связи с постоянно растущими объемами обрабатываемой информации, а также повышающимися требованиями к оперативности их обработки. Таким образом, в ближайшем будущем необходимо уделять особое внимание созданию подсистем СППР, которые будут в состоянии решать подобные задачи.Список литературы1. Power D.J. Web-based and model-driven decision support systems: concepts and issues. Americas Conference on Information Systems, Long Beach, California, 2000.2. Гасанов Э. Э. О сложности поиска в базах данных // Искусственный интеллект: Межвузовский сборник трудов. — Саратов, Изд-во Саратовского университета, 1993. — С. 41−56.3. Codd E.F. Relational Database: A Practical Foundation for Productivity // Commun. of ACM. — 1982. — V. 25/ - № 2. — P. 140−155.4. Литвак Б. Г. Разработка управленческого решения — М.: Издательство «Дело», 2004. — 392 с.5. Thieranf R.J. Decision Support Systems for Effective Planing and Control. -Englewood Cliffs, N. J: Prentice Hall, Inc, 1982.
Показать Свернутьsinp.com.ua
