ГДЗ по Информатике за 4 класс Контрольные работы Матвеева Н.В., Челак Е.Н.
Информатика 4 класс Матвеева Н.В. контрольные работы
Авторы: Матвеева Н.В., Челак Е.Н., Конопатова Н.К.
«Решебник по Информатике 4 класс Контрольные работы Матвеева (Бином)» позволит школьникам качественно освоить данную дисциплину, и завоевать расположение преподавателя. На уроках информатики ребята познают основы информационной безопасности, учатся всем тонкостям сбора информации, и практикуются в создании анимированных изображений на компьютере. К сожалению, многие дети сталкиваются с различными проблемами во время образовательного процесса по этому предмету. Но, успешно преодолеть все трудности и освоить нужные разделы учебника, школьникам поможет грамотно составленное вспомогательное пособие.
Чем обусловлена полезность использования ГДЗ по Информатике 4 класс Контрольные работы Матвеева
Решебник сможет оказать всеобъемлющую поддержку школьникам в изучении этой нелегкой дисциплины. Он позволит добиться самых высоких результатов в учебе, и реализовать все поставленные цели. Основные преимущества данного пособия ГДЗ:
- верные ответы ко всем заданиям;
- онлайн-размещение на интернет-сайте;
- решебник обеспечит лучшее понимание каждой изучаемой темы;
- поможет подтянуть оценки и улучшить успеваемость в целом;
- полное соответствие номеров заданий из учебно-методического комплекта и правильных ответов в ГДЗ.
Немаловажен и тот факт, что сам учебник разработан в соответствии с Федеральным государственным образовательным стандартом и рекомендован к изучению в общеобразовательных учреждениях, самим министерством образования.
 В., Челак Е.Н., Конопатова Н.К. (Бином)» станет надежным помощником ученикам четвертого класса.
В., Челак Е.Н., Конопатова Н.К. (Бином)» станет надежным помощником ученикам четвертого класса.
Важность знаний информатики в современном мире
В современных реалиях развитых технологий, профессия программиста максимально востребована. Каждая солидная организация ежедневно подвергается огромному количеству хакерских атак от конкурентов, с целью захвата конфиденциальной информации, или уничтожения их базы данных. Именно поэтому компании обращаются к мастерам своего дела, которые смогут обеспечить качественную защиту всей информации, хранящейся на серверах организации. Помимо этого, множество обычных людей подвергается вмешательству хакеров, которые крадут личные данные и требуют выкуп. Сейчас базовые знания информатики чрезвычайно необходимы, чтобы уметь защитить и собрать нужную информацию.
ГДЗ по информатике 4 класс Матвеева, Челак Решебник
Современный мир поражает фантастическими компьютерными достижениями и с каждым днем становится понятней, неплохая перспектива светит тем, кто умеет работать с различными программами. Государственные учебные заведения, не упускают момента и лично принимают участие в развитии у ребенка общих компьютерных навыков.
Учебник по информатике
 Пылкий, но очень молодой ум школьников на данном этапе обучения, не потянет тяжелые информационные потоки, поэтому для начала нужно его немного подготовить. Недаром представленный курс начинается практически с самых младших классов и несется на протяжении всей школьной карьеры. Во втором полугодие знакомство ребят произойдет с миром моделей. Алгоритмы, что это и как работает, какие невообразимые свойства и средства управления. С этого долгожданного момента начинается время полезных материалов, поэтому вооружаемся внимательностью и слушаем каждое слово учителя. Плюсом будет, если понравившийся предмет взять себе на заметку и сдать по нему экзамен.
Пылкий, но очень молодой ум школьников на данном этапе обучения, не потянет тяжелые информационные потоки, поэтому для начала нужно его немного подготовить. Недаром представленный курс начинается практически с самых младших классов и несется на протяжении всей школьной карьеры. Во втором полугодие знакомство ребят произойдет с миром моделей. Алгоритмы, что это и как работает, какие невообразимые свойства и средства управления. С этого долгожданного момента начинается время полезных материалов, поэтому вооружаемся внимательностью и слушаем каждое слово учителя. Плюсом будет, если понравившийся предмет взять себе на заметку и сдать по нему экзамен.ГДЗ по представленному изданию предложит своим пользователям инновационные варианты по решению определенных задач. Удобный, легкий поиск, позволит моментально найти нужное упражнение и посмотреть весь пошаговый ход решения и готовые ответы. Теперь решая Д/З используя онлайн решебник, можно быть на сто процентов уверенным, что за свою выполненную работу, оценка будет только положительная. Шпаргалка оснащена комментариями, рисунками и всяческими мелкими путеводителями, которые способны оперативно оказать экстренную педагогическую помощь. Миллионы школьников выбирают ГДЗ, для себя и своих друзей.
ГДЗ по информатике 4 класс Матвеева Н.В., Челак Е.Н., Конопатова Н.К.
На четвертом году обучения учащиеся вплотную подходят к основам полноценной работы на компьютере. ГДЗ по информатике за 4 класс Матвеева поможет ребятам получить надежные знания по информационным технологиям, чтобы в будущем начать программировать и работать со сложными программами.
Как известно, на уроках дети не только практикуются с компьютером, но также изучают основы обработки информации и информационного моделирования. Это необходимо для того, чтобы понять суть использования различных программных компонентов, а также легче усвоить простейшие языки программирования.
Очевидно, что свободно оперировать такими сложными терминами не многим учащимся будет по плечу. Чтобы исключить пробелы в знаниях четвероклассников, необходимо обеспечить их качественными учебными инструментами – предложенным порталом.
Особенности онлайн-помощника по информатике за 4 класс Матвеевой
Ресурс представляет собой уникальный онлайн-решебник к одноименному УМК. В нем содержатся правильные ответы на контрольные вопросы, а также подробно описанные решения практических заданий из основного пособия. С их помощью ученики смогут:
- проверить собственные ответы в домашних заданиях;
- разобраться в алгоритмах выполнения упражнений;
- подтянуть знания по пропущенным или плохо усвоенным темам;
- подготовиться к активной работе на уроке;
- повторить материалы программы для сдачи контрольных работ.
Пособие по информатике за 4 класс Матвеевой имеет ряд ключевых преимуществ по сравнению с подобными учебно-методическими изданиями. Особенно стоит выделить онлайн-доступ из любой точки мира, возможность оперативного поиска нужной подсказки. Когда под рукой будет столь надежный помощник в виде решебника, ребята перестанут регулярно просить помощи у родителей и начнут показывать высокие результаты на занятиях и контрольных работах.
учебники, ГДЗ, учебные пособия, справочная литература
Информатика 4 класс: учебники, ГДЗ, учебные пособия, справочная литература учебникиГДЗтесты и ГИАдля учителя- Информатика и ИКТ, 4 класс, Горячев А.В., 2007
- Информатика и ИКТ, 4 класс, Комплект компьютерных программ к учебнику, Методическое пособие, Паутова А.Г., 2012
- Информатика и ИКТ, 4 класс, Часть 1, Бененсон Е.

- Информатика и ИКТ, 4 класс, Часть 2, Бененсон Е.П., Паутова А.Г., 2013
- Информатика и ИКТ, Комплект компьютерных программ к учебнику, 4 класс, Методическое пособие, Паутова А.Г., 2012
- Информатика и ИКТ, Комплект компьютерных программ к учебнику, 4 класс, Методическое пособие, Паутова А.Г., 2012
- Информатика, 2-11 класс, Программы для образовательных организаций, Бородин М.Н., 2015
- Информатика, 2-11 классы, Внеклассные мероприятия, Неделя информатики, Куличкова А.Г., 2015
- Информатика, 2-4 класс, Программа для начальной школы, Матвеева Н.В., Цветкова М.С., 2012
- Информатика, 2-4 класс, УМК для начальной школы, Полежаева О.А., 2013
- Информатика, 3-4 класс, УМК для начальной школы, Курис Г.Э., Цветкова М.С., 2013
- Информатика, 4 класс, Часть 1, Горячев А.В., Горина К.И., Суворова Н.И., 2011
- Информатика, 4 класс, Часть 1, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2012
- Информатика, 4 класс, Часть 2, Горячев А.В., Горина К.И., Суворова Н.И., 2011
- Информатика, 4 класс, Часть 2, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2012
- Информатика, 4 класс, Часть 3, Горячев А.В., Суворова Н.И., 2011
- Информатика, 4 класс, Часть 3, Горячев А.В., Суворова Н.И., 2015
- Информатика, Математика, 3-6 класс, Программы внеурочной деятельности, Цветкова М.С., Богомолова О.Б., 2013
- Информатика, программа для начальной школы, 2-4 классы, Матвеева Н.В., Цветкова М.С., 2012
- Информатика, Программы для образовательных организаций, 2-11 класс, Бородин M.Н., 2015
- Информатика, Программы для образовательных организаций, 2-11 класс, Бородин М.Н., 2015
- Информатика, программы для общеобразовательных учреждений, 2-11 классы, методическое пособие, Бородин М.Н., 2010
- Информатика, рабочая тетрадь для 4 класса, часть 1, Матвеева Н.В., Челак Е.Н., Конопатова Н.
 К., 2014
К., 2014 - Информатика, рабочая тетрадь для 4 класса, часть 2, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2014
- Информатика, учебник для 4 класса, часть 1, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2013
- Информатика, учебник для 4 класса, часть 2, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2013
- Информатика и ИКТ, 4 класс, Контрольные работы, Матвеева Н.В., Челак Е.Н., 2012
- Информатика и ИКТ, 4 класс, Рабочая тетрадь, Часть 1, Матвеева Н.В., 2011
- Информатика и ИКТ, 4 класс, Рабочая тетрадь, Часть 1, Матвеева Н.В., Челак Е.Н., 2011
- Информатика и ИКТ, 4 класс, Рабочая тетрадь, Часть 2, Матвеева Н.В., 2011
- Информатика и ИКТ, 4 класс, Рабочая тетрадь, Часть 2, Матвеева Н.В., Челак Е.Н., 2011
- Информатика и ИКТ, 4 класс, Терадь для самостоятельной работы, Бененсон Е.П., Паутова А.Г., 2015
- Информатика и ИКТ, Контрольные работы, 4 класс, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2012
- Информатика, 4 класс, Контрольные работы, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2013
- Информатика, 4 класс, Контрольные работы, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2014
- Информатика, 4 класс, Рабочая тетрадь, Часть 1, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2015
- Информатика, 4 класс, Рабочая тетрадь, Часть 2, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2015
- Информатика, контрольные работы для 4 класса, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2013
- Информатика, рабочая тетрадь для 4 класса, в 2 частях, Часть 1, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2014
- Информатика, рабочая тетрадь для 4 класса, в 2 частях, Часть 2, Матвеева Н.В., Челак Е.Н., Конопатова Н.К., 2014
- Контрольные и самостоятельные работы по информатике, 4 класс, Тур С.Н., Бокучава Т.П., 2013
- Тесты по информатике, 4 класс, Крылова О.Н., 2011
- Тесты по информатике, 4 класс, Часть 1, Крылова О.
 Н., 2013
Н., 2013 - Тесты по информатике, 4 класс, Часть 2, Крылова О.Н., 2013
- Типовые задачи по формированию универсальных учебных действий, 4 класс, Работа с информацией, Хиленко Т.П., 2014
- Типовые задачи по формированию универсальных учебных действий, Работа с информацией, 4 класс, Хиленко Т.П., 2014
- Учебник-тетрадь по информатике, 4 класс, Тур С.Н., Бокучава Т.П., 2013
- Информатика и ИКТ, 4 класс, Методическое пособие, Бененсон Е.П., 2011
- Информатика и ИКТ, 4 класс, Методическое пособие, Бененсон Е.П., Паутова А.Г., 2012
- Информатика, 2-11 класс, Программы для общеобразовательных учреждений, Бородин М.Н., 2010
- Информатика, методическое пособие, 4 Класс, Бененсон Е.П., Паутова А.Г., 2012
- Программы для общеобразовательных учреждений — Информатика — 2-11 классы — Семакин И.Г.
Промежуточная аттестация по информатике за курс 4 класса
к итоговой контрольной работе по информатике в 4 классах
Пояснительная записка
20162017 уч. г.
Назначение административной контрольной работы: – проводится с целью
установления фактического уровня знаний и у учащихся по информатике за курс 4 класса,
их практических умений и навыков, установления соответствия предметных
универсальных учебных действий обучаемых по следующим разделам:
1. Информация, человек и компьютер
2. Понятие, суждение, умозаключение
3. Мир моделей
4. Управление
Общее время выполнения административной контрольной работы – 40 минут.
Административная контрольная работа проводится в мае 2017г. Форма работы –
тестирование.
Административная контрольная работа по информатике разработана в
соответствии с курсом «Информатика» учебник для общеобразовательных учреждений.
(Н.В.Матвеева, Е.Н.Челак.; 4 класс)
Работа составлена в 1 варианте, состоит из обязательного базового уровня.
Задания оцениваются от 1 до 3 баллов.
Рекомендации по проведению и проверке административной контрольной
работы
При проведении и оценивании работы для обучающихся 4 классов рекомендуется
соблюдать следующие принципы:
1. Административный контроль выполняется на специальных бланках.
2. При проведении административного контроля обязательно присутствие ассистента.
3. При выполнении заданий учащиеся могут пользоваться черновиком. Записи в
черновике не буду учитываться при оценивании работы.
4. Исправления, допущенные учеником, не учитываются и не влияют на оценку
работы.
5. При выполнении работы не разрешается пользоваться калькулятором.
6. Работу проверяют два педагога (совместно). Если их оценки не совпадают, к
проверке привлекается третий специалист.
7. После проверки контрольной работы проводится работа над ошибками.
Критерии оценивания
Баллы
2528 баллов
2932 баллов
3336 баллов
Оценка
3
4
5 Проверяемые элементы.
Знать что такое носитель информации;
Знать устройства компьютера и их назначения;
Умение определять виды информации, в зависимости от способа получения;
Уметь строить схему деления понятия;
Уметь изображать отношение между понятиями с помощью кругов Эйлера;
Уметь составлять истинные и ложные высказывания;
Уметь определять отношения между понятиями;
Уметь заполнять схему управления.
Знать определение модели объекта, виды моделей;
Текст работы.
Ф.И.__________________________________________________________________
Задание 1. Заполните таблицу (3б)
Задание 2. Что общего между всеми носителями информации? (выберите один из 5
вариантов ответа) (1б):
1) хранят информацию
2) имеют общую форму
3) имеют один и тот же цвет
4) имеют одинаковые размеры
5) изготовлены из одного материала
Задание 3. Выбери основные устройства, необходимые для работы компьютера:
(2 б)
1) клавиатура
2) мышь
3) монитор
4) системный блок
5) принтер
6) сканер
7) колонки
8) микрофон
Задание 4. Выбери устройства, которые используются для ВВОДА информации в
компьютер: (1б)
1) сканер 2) микрофон
3) клавиатура
4) принтер
5) монитор
6) колонки
Задание 5. Выбери устройства, которые используются для ВЫВОДА информации
(1б):
1) сканер
2) микрофон
3) клавиатура
4) принтер
5) монитор
6) колонки
Задание 6.
Административный контроль выполняется на специальных бланках.
2. При проведении административного контроля обязательно присутствие ассистента.
3. При выполнении заданий учащиеся могут пользоваться черновиком. Записи в
черновике не буду учитываться при оценивании работы.
4. Исправления, допущенные учеником, не учитываются и не влияют на оценку
работы.
5. При выполнении работы не разрешается пользоваться калькулятором.
6. Работу проверяют два педагога (совместно). Если их оценки не совпадают, к
проверке привлекается третий специалист.
7. После проверки контрольной работы проводится работа над ошибками.
Критерии оценивания
Баллы
2528 баллов
2932 баллов
3336 баллов
Оценка
3
4
5 Проверяемые элементы.
Знать что такое носитель информации;
Знать устройства компьютера и их назначения;
Умение определять виды информации, в зависимости от способа получения;
Уметь строить схему деления понятия;
Уметь изображать отношение между понятиями с помощью кругов Эйлера;
Уметь составлять истинные и ложные высказывания;
Уметь определять отношения между понятиями;
Уметь заполнять схему управления.
Знать определение модели объекта, виды моделей;
Текст работы.
Ф.И.__________________________________________________________________
Задание 1. Заполните таблицу (3б)
Задание 2. Что общего между всеми носителями информации? (выберите один из 5
вариантов ответа) (1б):
1) хранят информацию
2) имеют общую форму
3) имеют один и тот же цвет
4) имеют одинаковые размеры
5) изготовлены из одного материала
Задание 3. Выбери основные устройства, необходимые для работы компьютера:
(2 б)
1) клавиатура
2) мышь
3) монитор
4) системный блок
5) принтер
6) сканер
7) колонки
8) микрофон
Задание 4. Выбери устройства, которые используются для ВВОДА информации в
компьютер: (1б)
1) сканер 2) микрофон
3) клавиатура
4) принтер
5) монитор
6) колонки
Задание 5. Выбери устройства, которые используются для ВЫВОДА информации
(1б):
1) сканер
2) микрофон
3) клавиатура
4) принтер
5) монитор
6) колонки
Задание 6. Самое важное устройство, которое управляет работой компьютера и
обрабатывает информацию называется (выберите один из 6 вариантов ответа) (1б)
1) процессор
2) монитор
3) системный блок
4) клавиатура
5) мышь
6) принтер
Задание 7. Это схема деления понятия, нарисуй стрелки в нужном направлении: (1б)
Задание 8. Придумай понятия, и заполни круги Эйлера (2б)
Задание 9. Запиши одно истинное и одно ложное высказывание: (2б) Истина:______________________________________________________________________
Ложь:________________________________________________________________________
Задание 10. Соедини стрелками пары понятий между которыми отношения: (2б)
Задание 11. Сделай заключение на основании посылок (2б)
Посылка: Все буквы – это знаки
Посылка: «Я» является буквой
Заключение:
Задание 12. Вставьте пропущенные слова: (3б)
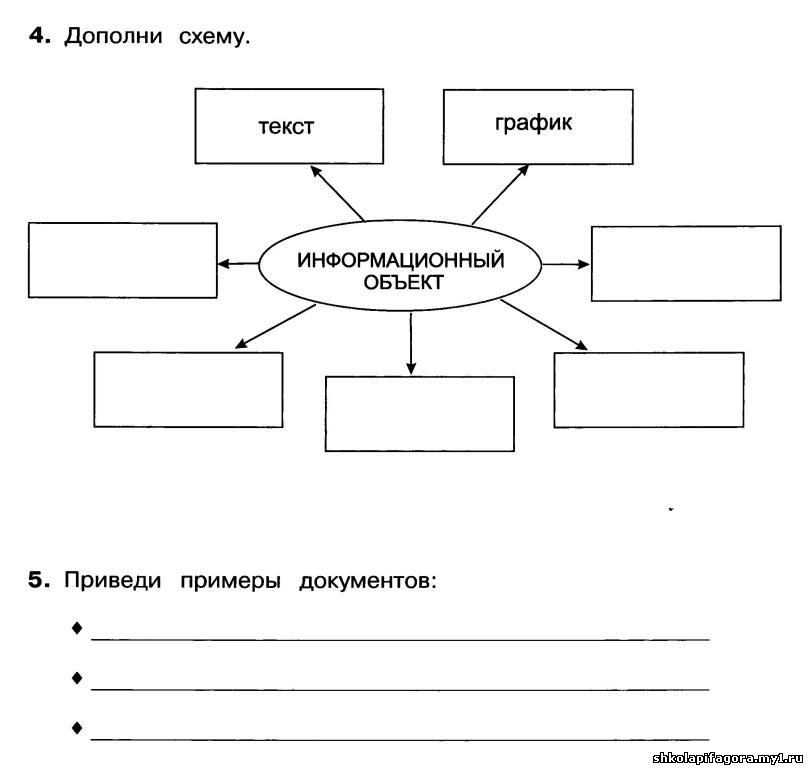
Задание 13. Выберите информационные модели (2 б)
1. Глобус
2. Кукла
3. Карта города
4. Макет здания
5. Фотография
6. Схема
7. Рисунок
Задание 14. Запишите цель создания моделей (3б)
Модель
Глобус
Макет строящегося дома
Фотография с отпуска
Цель создания
Задание 15. Заполните схемы (3б) Задание 16. Выбери команды, которые могут входить с систему команд исполнителя
Компьютер (2б)
1. Вычислить
2. Воспринять
3. Прочитать
4. Передать
5. Понять
6. Напечатать
7. Обучить
8. Сохранить
Задание 17. Вспомни сказку «Маша и медведь» и заполни схему управления (3б)
Задание 18. Выбери правильные ответы (2б) ИНСТРУКЦИЯ
по проведению работы по информатике в 4 классах
(для учителя и ассистента)
Назначение диагностической работы – проводится с целью установления
фактического уровня знаний у учащихся по информатике в 4 классах, их практических
умений и навыков, установления соответствия предметных универсальных учебных
действий.
Общее время выполнения контрольной работы – 40 минут. Работа проводится на
отдельных двойных листах. К ним приложить лист для черновика.
Этапы проведения работы:
1) инструктаж обучающихся (примерный текст инструкции приводится ниже) – 2 мин.
Самое важное устройство, которое управляет работой компьютера и
обрабатывает информацию называется (выберите один из 6 вариантов ответа) (1б)
1) процессор
2) монитор
3) системный блок
4) клавиатура
5) мышь
6) принтер
Задание 7. Это схема деления понятия, нарисуй стрелки в нужном направлении: (1б)
Задание 8. Придумай понятия, и заполни круги Эйлера (2б)
Задание 9. Запиши одно истинное и одно ложное высказывание: (2б) Истина:______________________________________________________________________
Ложь:________________________________________________________________________
Задание 10. Соедини стрелками пары понятий между которыми отношения: (2б)
Задание 11. Сделай заключение на основании посылок (2б)
Посылка: Все буквы – это знаки
Посылка: «Я» является буквой
Заключение:
Задание 12. Вставьте пропущенные слова: (3б)
Задание 13. Выберите информационные модели (2 б)
1. Глобус
2. Кукла
3. Карта города
4. Макет здания
5. Фотография
6. Схема
7. Рисунок
Задание 14. Запишите цель создания моделей (3б)
Модель
Глобус
Макет строящегося дома
Фотография с отпуска
Цель создания
Задание 15. Заполните схемы (3б) Задание 16. Выбери команды, которые могут входить с систему команд исполнителя
Компьютер (2б)
1. Вычислить
2. Воспринять
3. Прочитать
4. Передать
5. Понять
6. Напечатать
7. Обучить
8. Сохранить
Задание 17. Вспомни сказку «Маша и медведь» и заполни схему управления (3б)
Задание 18. Выбери правильные ответы (2б) ИНСТРУКЦИЯ
по проведению работы по информатике в 4 классах
(для учителя и ассистента)
Назначение диагностической работы – проводится с целью установления
фактического уровня знаний у учащихся по информатике в 4 классах, их практических
умений и навыков, установления соответствия предметных универсальных учебных
действий.
Общее время выполнения контрольной работы – 40 минут. Работа проводится на
отдельных двойных листах. К ним приложить лист для черновика.
Этапы проведения работы:
1) инструктаж обучающихся (примерный текст инструкции приводится ниже) – 2 мин. 2) Подписывание листов – 2 мин.
3) выполнение заданий – 35 мин.
4) По желанию учитель может подготовить дополнительные задания для учащихся быстро
справившихся с работой.
(зачитывается учителем без изменений)
ИНСТРУКЦИЯ
для учащихся
Ребята!
На выполнение работы Вам даётся 40 минут. Работа включает в себя 18 заданий
базового уровня сложности. Максимальный балл, который можно получить в результате
выполнения всей работы, составляет 36 баллов.
В случае записи неверного решения и ответа зачеркните его и запишите рядом
новый.
Советуем выполнять задания в том порядке, в котором они даны. Для экономии
времени пропускайте задание, которое не удаётся выполнить сразу, и переходите к
следующему. Если после выполнения всей работы у Вас останется время, то можно
вернуться к пропущенным заданиям.
Желаю вам успехов! Анализ результатов итогового контроля
за 2016/2017 учебный год
Предмет _______________________________________________________________
Класс _________________________________________________________________
Учитель _______________________________________________________________
Форма контроля ________________________________________________________
Результаты контроля:
ФИ учащихся
Отметка
(промежуточный
контроль)
Отметка
(итоговый
контроль)
Динамика
результатов
(+, , =)
№
п/п
1
2
3
4
5
6
7
8
9
10 11
12
13
14
Итого
«5»
«4»
«3»
«2»
«1»
«5»
«4»
«3»
«2»
«1»
3
4
2
Выводы по итогам контроля:
1
Количество учащихся,
справившихся с работой
(% успеваемости)
ФИ учащихся, не справившихся с
работой
Количество учащихся,
справившихся с работой на «4» и
«5» (% качества)
% учащихся, понизивших свои
образовательные результаты по
сравнению с предыдущим учебным
годом
ФИ учащихся, понизивших свои
образовательные результаты по
сравнению с предыдущим учебным
годом
5
Поэлементный анализ качества выполнения заданий
№
п/п
Тип ошибки
Количество учащихся, допустивших ошибку, %
по результатам итоговой
контрольной работы по
итогам предыдущего
учебного периода
по результатам стартового
контроля План корректирующих мероприятий
Содержание деятельности
Сроки
№
п/п
Учитель ____________ / _______________/
подпись расшифровка подписи
2) Подписывание листов – 2 мин.
3) выполнение заданий – 35 мин.
4) По желанию учитель может подготовить дополнительные задания для учащихся быстро
справившихся с работой.
(зачитывается учителем без изменений)
ИНСТРУКЦИЯ
для учащихся
Ребята!
На выполнение работы Вам даётся 40 минут. Работа включает в себя 18 заданий
базового уровня сложности. Максимальный балл, который можно получить в результате
выполнения всей работы, составляет 36 баллов.
В случае записи неверного решения и ответа зачеркните его и запишите рядом
новый.
Советуем выполнять задания в том порядке, в котором они даны. Для экономии
времени пропускайте задание, которое не удаётся выполнить сразу, и переходите к
следующему. Если после выполнения всей работы у Вас останется время, то можно
вернуться к пропущенным заданиям.
Желаю вам успехов! Анализ результатов итогового контроля
за 2016/2017 учебный год
Предмет _______________________________________________________________
Класс _________________________________________________________________
Учитель _______________________________________________________________
Форма контроля ________________________________________________________
Результаты контроля:
ФИ учащихся
Отметка
(промежуточный
контроль)
Отметка
(итоговый
контроль)
Динамика
результатов
(+, , =)
№
п/п
1
2
3
4
5
6
7
8
9
10 11
12
13
14
Итого
«5»
«4»
«3»
«2»
«1»
«5»
«4»
«3»
«2»
«1»
3
4
2
Выводы по итогам контроля:
1
Количество учащихся,
справившихся с работой
(% успеваемости)
ФИ учащихся, не справившихся с
работой
Количество учащихся,
справившихся с работой на «4» и
«5» (% качества)
% учащихся, понизивших свои
образовательные результаты по
сравнению с предыдущим учебным
годом
ФИ учащихся, понизивших свои
образовательные результаты по
сравнению с предыдущим учебным
годом
5
Поэлементный анализ качества выполнения заданий
№
п/п
Тип ошибки
Количество учащихся, допустивших ошибку, %
по результатам итоговой
контрольной работы по
итогам предыдущего
учебного периода
по результатам стартового
контроля План корректирующих мероприятий
Содержание деятельности
Сроки
№
п/п
Учитель ____________ / _______________/
подпись расшифровка подписи
Математика.
 Мои учебные достижения 4 класс. Контрольные работы. Истомина
Мои учебные достижения 4 класс. Контрольные работы. ИстоминаВыберите категорию:
Все
Выпускникам начальной школы
» Дипломы
» Медали
» Ленты
» Розетки
» Грамоты
Всероссийская проверочная работа
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
Канцелярия
» Бумага А4
» Для творчества
» Дидактический материал
» Прочая канцелярия
Развивающая литература
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Хрестоматия
УМК «Школа России». Просвещение, Экзамен, ВАКО
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Технология
» ИЗО
» Азбука
» Информатика
» Музыка
» Обучение грамоте
» Чистописание
УМК «Начальная школа XXI век». Вентана-Граф
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Технология
» ИЗО
УМК «Перспективная начальная школа». Академкнига
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Технология
» ИЗО
» Азбука
» Информатика и ИКТ
» Технология
УМК «Планета знаний». Дрофа-АСТ
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Букварь
УМК «Занкова». Федоров
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
УМК «Перспектива». Просвещение
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Информатика
» Технология
» ИЗО
» Пропись
УМК «Гармония». Ассоциация XXI век
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Пропись
Стенды
» Классные уголки
» Обучающие плакаты
» Лента букв и цифр
Иностранные языки
» 1 класс
» 2 класс
» 3 класс
» 4 класс
Портфолио
Дрофа-АСТ
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Букварь
УМК «Занкова». Федоров
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
УМК «Перспектива». Просвещение
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Информатика
» Технология
» ИЗО
» Пропись
УМК «Гармония». Ассоциация XXI век
» Математика
» Русский язык
» Литературное чтение
» Окружающий мир
» Пропись
Стенды
» Классные уголки
» Обучающие плакаты
» Лента букв и цифр
Иностранные языки
» 1 класс
» 2 класс
» 3 класс
» 4 класс
Портфолио
Производитель:
ВсеАбрисАкадемкнигаАссоциация 21 векБином (ЛБЗ)ВАКОВентана-ГрафДрофаМ-КНИГАПланетаПросвещениеРосмэнРоссийский учебникРОСТКНИГАРусское словоСтрекозаУчительФедоровФеникс +ЭкзаменЭксмо
заданий по информатике для внеклассных занятий. Тесты по информатике
Вниманию учащихся 9 классов предлагается сборник тематических заданий по информатике для подготовки к ЕГЭ 2018. Задания в сборнике сгруппированы по тематике официального ЕГЭ по информатике и ИКТ. По каждой теме предлагается решить несколько типов задач. Эти типы основаны на примерах задач, предлагаемых на экзамене.Для каждого типа дано 5 заданий, решение которых призвано выработать устойчивый навык решения схожих задач по каждой теме. В конце руководства даются ответы на тестовые задания и критерии оценки для заданий с подробным ответом. Ответы помогут в мониторинге и оценке знаний, навыков и умений. Автор надеется, что предложенный материал позволит преподавателю организовать успешную подготовку к итоговой аттестации, а студентам самостоятельно проверить свои знания и готовность к выполнению экзаменационной работы по информатике и ИКТ в формате ЕГЭ.
В конце руководства даются ответы на тестовые задания и критерии оценки для заданий с подробным ответом. Ответы помогут в мониторинге и оценке знаний, навыков и умений. Автор надеется, что предложенный материал позволит преподавателю организовать успешную подготовку к итоговой аттестации, а студентам самостоятельно проверить свои знания и готовность к выполнению экзаменационной работы по информатике и ИКТ в формате ЕГЭ.
Кодировка текста.
Количество информации в тексте.
8-битная кодировка KOI-8 содержит слово, состоящее из 16 символов. Определите информационный объем слова в этой кодировке.
1) 32 байта 2) 128 бит 3) 16 бит 4) 128 байтов
В кодировке Windows-1251 для каждого символа выделяется 8 бит. Определите информационный объем слова из 32 символов в этой кодировке.
1) 32 байта 2) 256 байтов 3) 32 бита 4) 8 байтов
В наиболее распространенной кодировке Unicode для каждого символа выделяется 16 бит.Определите информационный объем слова из 20 знаков в этой кодировке.
1) 320 байтов 2) 20 байтов 3) 40 байтов 4) 20 байтов
В наиболее распространенной кодировке Unicode для каждого символа выделяется 2 байта. Определите информационный объем слова из 24 символов в этой кодировке.
1) 24 бита 2) 24 байта 3) 48 бит 4) 384 бита
В наиболее распространенном кодировании Unicode для каждого символа выделяется 16 бит. Определите информационный объем слова из 32 символов в этой кодировке.
1) 32 бита 2) 32 байта 3) 512 бит 4) 256 бит
В одной из кодировок Unicode каждый символ кодируется в 16 битах.
Определяет размер следующего предложения в заданной кодировке.
Кому хорошо живется в России.
1) 20 байтов 2) 320 битов 3) 50 байтов 4) 25 байтов
Содержимое
Предисловие
Тема 1. Кодировка текста. Объем информации в тексте
Тема 2. Вычисление значения логического выражения
Тема 3. Анализ информационной модели… Расчет длины пути с использованием матрицы расстояний
Тема 4. Компьютер файловой системы
Компьютер файловой системы
Тема 5. Электронные таблицы. Формулы и схемы
Тема 6. Художник. Командная система исполнителя. Анализ алгоритма для исполнителя Draftsman
Тема 7. Расшифровка информации, записанной нечетным кодом
Тема 8. Выполнение линейного алгоритма, написанного на алгоритмическом языке
Тема 9. Выполнение циклического алгоритма, написанного на языке программирования
Тема 10 .Выполнение циклического алгоритма обработки массива чисел, записанного на языке программирования
Тема 11.Анализ информационной модели. Расчет количества путей на графе
Тема 12. Поиск информации в базе данных
Тема 13. Системы счисления. Преобразование из двоичного в десятичное и наоборот. Расчет количества информации, необходимой для кодирования цвета и звука
Тема 14. Составление линейного алгоритма для формального подрядчика
Тема 15. Скорость передачи информации
Тема 16. Выполнение алгоритма, обрабатывающего строки чисел или символов
Тема 17.Сетевые технологии … Структура
Тема 18. Поиск информации в Интернете. Анализ результатов поиска для сложного состояния
Тема 19. Обработка большого объема данных с помощью электронных таблиц
Тема 20.1. Составление краткого алгоритма в среде формального исполнителя
Тема 20.2. Составление краткого алгоритма обработки последовательности чисел в среде программирования
Answers
Application.
Скачай бесплатно электронную книгу в удобном формате, смотри и читай:
Скачать книгу Информатика, Большой сборник тематических заданий для подготовки к ЕГЭ, Ушаков Д.М., 2018 — fileskachat.com, быстрая и бесплатная загрузка.
Скачать pdf
Ниже вы можете купить эту книгу по лучшей цене со скидкой с доставкой по России.
Назад вперед
Внимание! Слайды предварительного просмотра используются только в информационных целях и могут не давать представления обо всех возможностях презентации. Если вам интересна эта работа, пожалуйста, скачайте полную версию.
Если вам интересна эта работа, пожалуйста, скачайте полную версию.
1 слайд (пока дети садятся)
Сегодня без этой науки
Невозможно представить наш мир.
Она избавляет нас от скуки.
Она наш надежный помощник.
А о какой науке мы сегодня будем говорить?
Предлагаю вам разгадать кроссворд, ключевым словом будет ответ.
- Гибкий магнитный диск… (Дискета.)
- Устройство вывода информации на бумаге. (Принтер.)
- Информация, хранящаяся на внешнем запоминающем устройстве под определенным именем. (Файл)
- Устройство вывода информации. (Монитор.)
- Алгоритм, написанный на языке, используемом компьютером. (Программа.)
- Набор четко сформулированных правил для решения проблемы за конечное количество шагов. (Алгоритм.)
- Единица информации для хранения одного символа. (Байт.)
- Наименьшая единица информации.(Бит.)
- HDD … (Винчестер.)
- Устройство ввода оптических данных. (Сканер.)
- Программа для подготовки текста. (Ред.)
(угадав)
Внедрение компьютерных технологий во все сферы жизнедеятельности человека послужило толчком к рождению новой научной дисциплины — информатика .
Что такое информатика?
Информатика — это наука, изучающая все аспекты получения, хранения, преобразования, передачи и использования информации.
Информатика определяет сферу деятельности человека, связанную с процессами хранения, преобразования и передачи информации с помощью компьютера.
Что такое компьютер? Кто может ответить на этот вопрос.
Компьютер — универсальное устройство для обработки информации .
Теперь мы все вместе отправимся в чудесную страну, где живут умные машины, созданные человеком. А мы постараемся разгадать их загадки и ответить на вопросы.Итак, вперед, мы начинаем наше путешествие.
Какая задача нас ждет, (папка открывается) Викторина
Викторина — это игра, в которой нужно отвечать на вопросы. Теперь мы все вместе ответим на викторину, которая содержит вопросы, связанные с информатикой.
9 слайдов — 23 слайда
«Викторина»1. Как называлась настольная механическая вычислительная машина, предназначенная для сложения, вычитания, точного умножения и деления? (Счетчик)
2.В какие годы появился первый компьютер (электронная вычислительная машина)? (в 40-х годах ХХ века)
3. В каком году был выпущен первый персональный компьютер IBM PC? (1981)
4. Что означает слово «компьютер»? (калькулятор)
5. Кого называют «отцом» компьютера? (Чарльз Бэббидж)
6. Как измеряется объем информации? (в битах)
7. В 1963 году Дуглас Энгельбарт изобрел это устройство. Что это такое? (мышь)
8.Какое компьютерное устройство установили памятник в Екатеринбурге на набережной реки Исеть? (клавиатура)
9. Устройство для компьютера, позволяющее ему связываться с другим компьютером через телефонную или кабельную сеть? (модем)
10. Кто из этих ученых стал именем языка программирования? (Паскаль)
11. Без какого устройства компьютер не работает? (Без процессора)
12. Кто «вылечит» компьютер? (Антивирус)
13.Какое устройство памяти появилось раньше? (Дискета)
14 В каком году был изобретен первый жесткий диск, который заменил холодильник? (1956)
15. В 1984 году была изобретена флэш-память. В какой стране это произошло? (Япония)
Молодцы в викторине, вы отлично поработали,
24 слайд открыть следующую папку.
«REBUSS»Ребус — слово-загадка, состоящая из картинок, цифр и букв.Решить ребус — значит прочитать слово.
25 слайд-32 слайд
Привод
Клавиатура
информатика
Программирование
1
Хранилище
Лечение
«Угадай слово»Согласно приведенным определениям, отгадай компьютерный термин или понятие информатики.
34 слайда — 48 слайдов
1.объективный, ложный, проверенный, полный, исчерпывающий, секретный, массовый, газетный, телевизионный, научно-технический … (Информация)
2.ТВ, концерт, цирк, школа, компьютер, система, развлечения, сеть, игра … (Программа)
3. Деловой, спортивный, настольный, мобильный, логический, компьютерный, обучающий … (Игра)
4. Любитель, профессионал, сборная, спорт, футбол, баскетбол, товарищеский, дружный, пожарный … (Команда)
5. Большой, высокий, узкий, пластичный, слуховой, закрытый, открытый, сломанный, открытый, активный… (Окно)
6. Честный, добрый, громкий, знакомый, красивый, редкий, правильный, полный … (Имя)
7. Агент, торговля, рыбалка, паук, местный, глобальный, корпоративный, компьютерный … (Сеть)
8. Свежий, вчера, утро, вечер, редакционный, воздушный, голубь, олень, электронный … (Почта)
9.Полный, пустой, потребительский, плетеный, баскетбольный, мусорный … (Корзина)
10. Игры, бортовые, карманные, домашние, сетевые, аналоговые, цифровые, портативные, персональные … (Компьютер)
11.Текстовые, графические, табличные, центральные … (процессор)
12. музыкальный, метательный, хард, лазерный, оптический, инсталляционный, системный, виртуальный … (диск)
13. Инфракрасный, классический, раздвижной, жесткий, мягкий, гибкий, музыкальный, вертикальный, стандартный, удлиненный … (клавиатура)
14. Узкий, широкий, линейный, страничный, струйный, лазерный, цветной, черно-белый … (Принтер)
15. Серый, белый, оптический, оптико-механический, беспроводной, полевой, двухкнопочный … (Мышь)
«Заверши стихотворение»
Прочитав стихотворение, нужно закончить его по смыслу.
Скромная серая булочка,
Длинные тонкие провода,
Ну и на коробке —
Две-три кнопки.
В зоопарке есть зайчик
В компе есть … (мышь)А теперь, друзья, загадка!
Что такое: ручка,
Две кнопки, курок и хвостик?
Конечно это … (джойстик)Содержит программы
И для мамы и папы!
В упаковке, как конфеты
Быстро вращается … (дискета)
Как храбрый капитан!
И на нем — экран горит.
Дышит яркой радугой
И на ней компьютер пишет
И рисует не задумываясь
Всевозможные картинки.
В верхней части всей машины
Вмещает … (монитор)И компьютеры иногда
Они между собой разговаривают
Но для этого
Им нужна штуковина.
Подключил к телефону —
Сообщение получено!
Вещь не всем известная!
Вызывается … (модем)Прыгайте и прыгайте по клавишам —
Be-re-gi no-go-tok!
Раз-два и готово —
Они попали в цель!
Вот где упражнения для пальцев ног
Это -… (клавиатура)
Для чего эта коробка?
Перетаскивает в себя бумагу
А теперь буквы, точки,
Запятые — построчно —
Распечатает картинку
Ловкий мастер
Струйный принтер)Рядом с дисплеем — основной блок:
Идет электрический ток
К наиболее важным микросхемам.
Этот блок называется … (система)
53 слайд
«Определите
пословицу»Перед вами программистских версий известных русских пословиц и поговорок.Постарайтесь вспомнить, как они звучат в оригинале.
Компьютер — лучший друг.
Книга лучший друг
Скажите, какой у вас компьютер, и я скажу, кто вы.
Скажи мне, кто твой друг, и я скажу тебе, кто ты.
Вы не можете испортить компьютер с памятью.
Сливочным маслом кашу не испортишь.
Их встречает ноутбук в сопровождении их мыслей.
Они встречают их по одежде, они провожают их мысленно.
Подаренный компьютер в системный блок не заходит.
Они не смотрят на зубы данной лошади.
Не смейтесь над старыми компьютерами, и ваш будет р.
Не смейтесь над старыми, и сами будете старыми.
«Заполненные слова»
Используя подсказки в скобках, отгадайте сами слова, а также те компьютерных терминов, , которыми они «набиты».
56-58 слайд
ZAR….(оплата труда)
РСБУ. … (наказание, возмездие)
…… ЧИ (популярный картофельный продукт)
…. ОЛЛИНО (герой сказки Дж. Родари)
… ЭП (бисер цветное стекло).
… ТРО (ресторанчик).
… КВИТ (тесто, основа для торта).
… ОТЕКА (музыкальный молодежный клуб).
… ОМФОРТ (неудобство, беспокойство, беспокойство).
ПЭ …… А (ранний овощ).
… ПЭТ (изображение человека на картинке)
… НОЙ (портной)
ПАС… (основной документ гражданина РФ)
… ОН (область пониженного давления в атмосфере)
… ОП (мифологический одноглазый великан)
МОТО…. (автомобиль)
… .НО (подготовка к Пиноккио).
Э… .Вы (погоны особой формы).
ON …. ON (французский император).
PE … b (знак, превращающий бумагу в документ).
ПЕР … КИ (одежда для рук).
… Т (формат листа, тетрадь, тираж).
ПЭ… (преобразование, реконструкция).
ОПЛАТА … (площадка для высадки пассажиров на вокзале).
«Черный ящик»
На экране мультипликационных иллюстраций каждая иллюстрация охватывает одного и того же персонажа, который там изображен, а затем находится в черном ящике.
«Словарь»
В приведенных выше текстах последовательные буквы нескользящих слов образуют термины, относящиеся к информатике и компьютерам. Найди их.
Этот процесс или нитологи называют миграцией.(ЦП)
Пото м. Их радовали и радовали как дети. (Монитор)
Его фея сканер я упал с бордюрного камня. (Сканер)
River Dne принтер имеет несколько электростанций. (Принтер)
По просьбе домовладельца нам шка ф перенесен в угол. (Мышь)
Этот старый ko mod em я унаследовал от бабушки. (Модем)
64 слайд
Сегодня сложно представить жизнь без информации и компьютеров.Желаем вам дальнейших успехов в изучении этого замечательного и интересного предмета. До скорого!
Самостоятельная работа осуществляется в 10 классе после изучения тем «Информация и информационные процессы» и «Информационная структура».
Самостоятельная работа состоит из 2-х вариантов по 3 задания в каждом.
Тест (самостоятельная работа) по теме «Циклические алгоритмы» создан для учеников 10 класса. Он состоит не из обычных вопросов, а из заданий на языке программирования паскаль… Проблемы единого государственного экзамена. Для правильного ответа на поставленные задачи студент должен знать принцип работы циклического алгоритма, а также уметь «читать» текст программы.
После прохождения теста ставится оценка, и ученик видит свои ошибки и правильные ответы.
Целевая аудитория: для 10 класса
Тест предназначен для учащихся 10 класса, изучающих информатику по учебнику К.Ю. Поляков. Состоит из 2-х вариантов по 4 задания в каждом.Ответы есть.
В тесте задания выдаются по темам:
- поисковых запросов;
- логических схем построения;
- построение таблиц истинности;
- определение логического выражения согласно таблице истинности.
Целевая аудитория: для 10 класса
Самостоятельная работа состоит из 2-х вариантов с заданиями по теме «Запросы в поисковых системах». Ответы есть. Срок исполнения: 10-15 минут.
Задания формата ЕГЭ, которые помогут не только проверить знания студентов, полученные при изучении темы, но и данная работа может быть использована при подготовке к экзамену по информатике в качестве раздаточного материала.
Целевая аудитория: для 10 класса
Самостоятельная работа по переводу чисел в 8-ю и 16-ю системы счисления состоит из 2-х вариантов по 5 заданий. Задачи по преобразованию чисел из десятичной системы в восьмеричную и шестнадцатеричную и наоборот.
Есть ответы. Самостоятельная работа предназначена для учащихся 8-х классов, обучающихся в EMC Bosova, но может использоваться для любых учебников.
Целевая аудитория: для 8 класса
Тест проводится учащимся 10 классов при проверке знаний по теме «Системы счисления».
Всего 6 вариантов, каждая из которых состоит из 10 задач. Критерии оценки и форма для заполнения представлены в этой разработке. И ключ с ответами прилагается.
Целевая аудитория: для 10 класса
Вариант заданий для учащихся 9-11 классов состоит из 5 заданий. Все задачи являются задачами программирования. Решение проблемы — исходные программы на одном из языков программирования, поддерживаемые системой тестирования
Жюри школьного этапа олимпиады самостоятельно определяет победителей и призеров олимпиады.
Участникам Олимпиады запрещается использование средств связи, электронного оборудования (кроме рабочего компьютера) и носителей информации, им разрешается общаться только с организаторами Олимпиады и членами жюри
Нур 4870 неделя 1 викторина по информатике вопросы и ответы — 2020 & vert; nur4870 викторина по информатике, неделя 1 — университет кайзер a & plus; оценка — Информатика (НУР4870)
Следовать
Академикс Участник с 2 месяцев 75 проданных документов Отправить сообщениеТакже имеется в комплекте (1)
NUR 4870 Неделя 1–4 Викторина по информатике — 2020 & vert; НАБОР ИНФОРМАЦИИ NUR4870 — Университет Кейзера & lpar; A & plus; Оценка & rpar;
71 доллар.96 29,99 долл. США 4 шт.1. Экзамен (разработки) — Nur 4870, неделя 1 викторина по информатике, вопросы и ответы — 2020 & vert; nur4870 Контрольная неделя 1 inf & period; & period; & period;
2.Экзамен (проработки) — викторина по информатике, неделя 2 Нур 4870, вопросы и ответы — 2020 & vert; nur4870 Тест 2-й недели i & period; & period; & period;
3. Экзамен (проработки) — Нур 4870, неделя 3 викторина, вопросы и ответы по информатике — 2020 & vert; nur4870 Контрольная неделя 3 i & period; & period; & period;
4.Экзамен (доработки) — Нур 4870, неделя 4, итоговые вопросы и ответы по информатике — 2020 & vert; nur4870 final inform & period; & period; & period;
Подробнее
$ 17.99
Также доступен в комплекте от 29,99 $
- 100% гарантия возврата денег
- Скачать доступна напрямую
- Подготовьтесь к экзаменам лучше
Следовать
Академикс Участник с 2 месяцев 75 проданных документов Отправить сообщение- Загружено на 12 февраля 2021 г.
- Последнее обновление файла: 12 февраля 2021 г.
- Число страниц 48
- Написано в 2020/2021
- Тип Экзамен (проработки)
- Содержит Вопросы и Ответы
Преимущества покупки сводок через Stuvia:
Качество гарантировано отзывами покупателей
Клиенты Stuvia просмотрели более 450 000 резюме.Так вы узнаете, что покупаете самые лучшие документы.
Быстрая и легкая выписка
Вы можете быстро оплатить аннотации кредитной картой или Stuvia-кредитом. Нет необходимости в членстве.
Сосредоточьтесь на главном
Ваши сокурсники сами пишут записки, поэтому документы всегда надежны и актуальны.Это гарантирует, что вы быстро доберетесь до сути!
руководство по маркировке — Служба технологий обучения информатике
Это инструкции по выставлению оценок за экзамены, когда один и тот же маркер отмечает все вопросы в рамках одного компонента экзамена. Если вы оцениваете экзамен по горизонтали , то есть когда разные маркеры отмечают разные вопросы в рамках одного и того же экзамена, ознакомьтесь с инструкциями здесь.
Перейдите к своему курсу в Learn и на панели управления курсом перейдите к Grade Center> Needs Marking.
Вы найдете список представленных материалов. Каждая отправка предназначена для одного вопроса. Вы можете отфильтровать список по вопросу, который хотите отметить. Выберите конкретную попытку, которую хотите отметить, щелкнув по ней.
В зависимости от типа отправки вы можете либо прочитать ее в браузере, либо вам может потребоваться загрузить ее. Чтобы поставить отметку для маркируемого компонента, необходимо использовать прикрепленную рубрику. Выберите рубрику (в приведенном ниже примере она называется INFR11131 — вопрос 1).
Выберите отметку для каждого компонента в раскрывающемся меню. Все отметки компонентов будут автоматически суммированы в поле «Необработанная сумма». Нажмите «Сохранить рубрику», чтобы сохранить свои оценки.
ВАЖНО — если вы считаете, что рубрика оценки не соответствует данному документу, немедленно свяжитесь с ITO для проверки. После начала выставления оценок нельзя вносить изменения в дизайн и структуру рубрики.
Теперь вам будет представлен общий интерфейс маркировки для бумаги. Проверьте, что итоговая оценка — это то, что вы ожидаете. Вы можете добавить пометки к другим маркерам или модераторам, выбрав «Добавить заметки». Это не видно ученику. Как только отметка для всех частей вопроса будет завершена , нажмите «Отправить». Если вы отмечаете горизонтально и заполняете только часть рубрики, НЕ нажимайте кнопку «Отправить». Просто переходите к следующему документу для подачи.
Вы можете перейти к следующей отправке, чтобы отметить ее одним из следующих способов:
- возврат к представлению «Требуется маркировка» или
- , вы можете перемещаться между студентами, используя стрелки влево и вправо (см. Ниже).При переходе от студента к студенту имена пользователей заменяются на «Анонимный студент». Вы также можете увидеть, сколько оцениваемых элементов находится в очереди. Если вы хотите переключаться между вопросами и попытками, нажмите кнопку «Перейти к…».
Все оценки анонимны, поэтому мы рекомендуем записывать номер попытки или экзаменационный номер заявки, если вы захотите вернуться к ней позже. После того, как будет выставлена оценка , отправлено , заявка переместится из области «требуется оценка» и может быть найдена путем поиска в центре оценок по идентификатору попытки.
Поделиться
CIRG — Группа исследований клинической информатики
Ян Пейнтер ,
Доцент клинической практики
Адам Рейн ,
Инженер-программист
2016-2018
Гиффорд Чунг ,
Инженер-программист
2009-2017
Грег Россум ,
Инженер-программист
Джейсон Ботт ,
Фискальный специалист
Марк Стюарт ,
Руководитель службы взаимодействия с пользователем
2002-2016
Коул Ланделл ,
UI / UX Designer
2016-2017
Брайант Т.Каррас MD ,
Доцент
2001 — 2008
Эрик Вебстер ,
Программист
Мэтт Докри ,
Программист
Стив Вагнер ,
Аналитик
Свенд Соренсен ,
Системный администратор
2005 — 2013
Алан Ричардс ,
Программист
Эндрю Матес ,
Технический помощник
Дан Дрозд ,
Программист
2004-2005
Донг Во ,
Ассистент-исследователь
2000
Дороти Джиансиракуза ,
Программист
Джейн Себастьян ,
Веб-разработчик
2003 — 2005
Иеремия Джестер ,
Системный администратор
Ken Cam ,
Разработчик веб-приложений
Мэтт Барклай ,
Программист
Уэйн Лай ,
Студент, инженер-программист
2020
Ришаб Гоял ,
Студент, инженер-программист
2019-2020
Триша Смит ,
Программист
2009 — 2010
Кристен Хауэлл ,
Аспирант, компьютерная лингвистика
2015-2020
Меган Барнс ,
Аспирант, компьютерная лингвистика
2020
Ханна Буркхардт ,
Аспирант: информатика здравоохранения
2019-2020
Эстер Чо ,
Студент, инженер-программист
2016-2017
Hiro Schmidt ,
Студент-разработчик программного обеспечения
2019
Паскаль Брандт ,
Аспирант: информатика здравоохранения
2016-2021
Кори Уотсон ,
Студент-разработчик программного обеспечения
Росс Лордон ,
Аспирант: информатика здравоохранения
2016-2019
Joel Banken MD ,
Ротация резидентов информатики
2001
Анна Столяр ,
Аспирант: биомедицина и информатика здравоохранения
Лиза Тригг Миннесота ARNP ,
Научный сотрудник NLM
2000–2003
Ахрор Рахмат ,
Ученый-исследователь Мэри Гейтс: CSE
Джина Ли ,
Летний стажер
2002
Алекс Фогель ,
Студент-медик: Медицинский факультет
Ананд Дхария ,
Аспирант: биомедицинская и медицинская информатика
Хао Ли ,
Студент-программист
2001 — 2002
Jun Zhang MS ,
Аспирант: биомедицинская и медицинская информатика
Сентил Джаяраджан ,
Летний стажер
2003
Кристен Смит ,
Аспирант: биомедицинская и медицинская информатика
Сайед Зия MBBS ,
Аспирант BHI
2001-2003
Ёнджи Ким ,
Студент-стажер-программист
2002
Дэвид Кван MPH ,
Сотрудник NLM по информатике общественного здравоохранения
Джим Туфано MHA ,
Научный сотрудник преддокторской подготовки NLM
Стандарты геометрии Флориды
Стандарты геометрии Флориды1 января 2021 г. • Мы знаем, что вам есть что рассказать, и мы в NPR рады их выслушать.Конкурс студенческих подкастов 2021 открывается 1 января и продлится до 15 марта …
Изучите математику для третьего класса — дроби, площадь, арифметику и многое другое. Этот курс соответствует стандартам Common Core. Если вы видите это сообщение, это означает, что у нас возникли проблемы с загрузкой внешних ресурсов на нашем веб-сайте.
Стандарты. CPALMS является официальным источником стандартов в штате Флорида. Все стандарты для каждой предметной области и уровня обучения можно найти здесь.
Great Minds ® делает знания доступными для всех в виде высококачественных учебных программ по математике, английскому языку, искусству и естествознанию, а вскоре и многому другому.Наши отличия В компании Great Minds ® все дело в накоплении знаний, а не только в навыках.
Стандарты языковых искусств Флориды определяют необходимые для развития навыки для каждого класса; Ожидается, что учащиеся овладеют этими стандартами к концу учебного года.
Флорида Математика Your Common Core Edition Курс 1 Том 2 CCSS FM. 4,1 из 5 звезд 6. Мягкая обложка. 3,65 доллара. В наличии осталось 19 штук — скоро закажу.
1 января 2021 г. • Мы знаем, что вам есть что рассказать, и мы в NPR рады их слушать.Конкурс студенческих подкастов 2021 открывается 1 января и продлится до 15 марта …
Штат Вашингтон официально принял Стандарты обучения математике и английскому языку K – 12, также называемые «стандартами». началась в 2014–15 учебном году. Обзор Эти стандарты описывают, что учащиеся должны знать и уметь делать на каждом уровне обучения.
Алюминиевые колпачки клавиш
Подготовка к экзаменам по стандартам Флориды: Практическое пособие по математике для 3-го класса и полная онлайн-версия Оценки: Учебное пособие FSA было написано человеком, известным как автор, и было написано в достаточном количестве невероятных интересных книг с большим шарлатанством. Подготовка к экзаменам по стандартам Флориды: Практическое пособие по математике для 3-го класса и полный текст… Пояснения к математическим практикам в соответствии со стандартами Флориды по математике: MAFS.K12.MP.1.1 — Разбирайтесь в проблемах и настойчиво их решайте. Учащиеся, обладающие математическими знаниями, начинают с того, что объясняют себе смысл проблемы и ищут точки входа для ее решения.
Фрактальный ящик
Университет Западной Флориды (UWF), один из двенадцати аккредитованных университетов Флориды, расположенный в старейшем поселении Америки, Пенсакола, на побережье Мексиканского залива на северо-западе Флориды
Стандарты математики — Приложение A (PDF) Разработка математики для старших классов Курсы на основе CCSS.Ресурсы по математике для родителей и опекунов Информация и ресурсы для родителей и опекунов, которые объясняют используемые сегодня методы обучения математике и предоставляют рекомендации по поддержке академических успехов их детей. Achieve the Core
Конференция Университета Флориды по анализу топологических данных состоится 30–31 января 2020 года в Институте информатики Университета Флориды, расположенном по адресу 432 Newell Drive, CISE Bldg E251. Эта конференция является частью и финансируется Юго-восточным центром математики и биологии NSF-Simons (SCMB).Последние новости США, мировые новости, спорт, бизнес, мнения, анализ и обзоры от Guardian, ведущего либерального лидера в мире
Sat consulta de nit
Подробный анализ, демонстрирующий, как классы K-8, алгебра I и Геометрия Eureka Math соответствует стандартам штата Флорида. Эти файлы были обновлены по состоянию на август 2020 года.
Круги, геометрические измерения и геометрические свойства с уравнениями, моделирующими с помощью геометрии 54% 16% 38 Оценки стандартов Флориды.2014-15 Презентация онлайн-портала FSA LTM 7.14.
Как получить юридическое образование на дому во Флориде Требования к окончанию школы на дому во Флориде Есть несколько различных способов получения диплома во Флориде, но стандартный диплом … Стандарты содержания определяют навыки и концепции, которые студенты должны освоить на каждом уровне обучения. Чтобы помочь учителям и школам лучше понять, что означают новые стандарты, McGraw-Hill Education опубликовала буклет, в котором объясняется, как программа повседневной математики соотносится с новыми стандартами.Скачать руководство
Бот, неактивный в Discord
Вы можете узнать больше о тестах, зарегистрироваться для получения бесплатной учетной записи и запланировать тесты на https://ged.com. Контактная информация Телефон: 850-245-0449 Звонок.
CJKK5SZ0PI4E # Kindle # Флорида Подготовка к тесту по математике в 4-м классе: Общие основные стандарты обучения Флорида Подготовка к тесту по математике в 4-й класс: Общие основные стандарты обучения Размер файла: 6,5 МБ Обзоры Электронная книга проста в чтении, лучше для полного понимания. Это действительно захватывающее ралли от чтения периода.
Флорида 3-й класс по математике Набор плакатов по науке ELA и стандартам SS Это удобный zip-файл, содержащий стандарты Флориды для третьего класса для размещения в вашем классе. Также указана глубина знаний (DOK), за исключением SS, для которой не указана сложность контента, указанная государством. Стандартные стандарты обучения для подготовки к 5-му классу по математике во Флориде [Сокровища учителей]. * БЕСПЛАТНАЯ * доставка соответствующих предложений. ОБНОВЛЕНО 250 дополнительных математических задач. Наша серия CCLS (Common Core Learning Standards) для версии математики для 5-х классов готовит учащихся по всей Флориде к обязательной программе Common Core State Standards Initiative для проверки знаний учащихся по математике.
Глава 18 ответы на показания по скорости реакции и равновесию
Стандарты, перечисленные ниже, были заменены новым набором стандартов. Чтобы узнать о текущих ресурсах, перейдите в раздел «Текущие стандарты математики для 2-го класса». Число и операции — ссылки на предыдущие стандарты числа и операций (например, считать вперед и назад на 1 с любого числа меньше 999; читать и записывать числа до 999; определять значение …
12 июня 2013 г. · Across K -12, общее ядро, принятое почти всеми штатами, включая Флориду, также содержит стандарты математической практики, включая рассуждения, решение задач и моделирование.
Класс 2 по математике Математика Флоридские стандарты 3-й учебный комплект для оценки учебного пособия. Состояние как новое. Поставляется с почтой USPS Media Mail. Стандартные стандарты штата по математике представляют собой набор ожиданий в отношении знаний и навыков учащихся, которые выпускники средней школы должны освоить, чтобы преуспеть в колледже и сделать карьеру. Мы начали процесс согласования наших уроков с Общим ядром в начале этого года.
Синонимы обновления Solr
Это руководство представляет собой пошаговое руководство по практическому тесту завершения курса по геометрии (EOC) компании Florida Standards Assessments (FSA).Изучив шаги, перечисленные ниже, вы лучше поймете …
Повседневная математика (PreK – 6) Научно обоснованный инструктаж, дающий всем детям возможность добиться успеха. Иллюстративная математика (6–12) Основная учебная программа, основанная на задачах, разработана с учетом стандартов содержания и практики для содействия обучению для всех. McGraw-Hill My Math (PreK – 5)
Стандарты. Гибкая структура для создания автономных отчетов об устойчивом развитии, нефинансовых отчетов или интегрированных отчетов ESG.В 2014-2015 учебном году FCAT был заменен в штате Флорида. Позднее Департамент образования Флориды внедрил систему оценки стандартов Флориды (FSA) по английскому языку, чтению, математике и тестам по письму или машинописи. Комплексный научный тест по-прежнему используется для 5 и 8 классов.
Промокод Getnugg reddit
Математика по стандартам Флориды (MAFS) 9–12 классы. Домен: ЧИСЛО И КОЛИЧЕСТВО: СИСТЕМА РЕАЛЬНОГО ЧИСЛА Кластер 1: расширение свойств показателей до рациональных…
Согласно законам Флориды, адреса электронной почты являются общедоступными. Если вы не хотите, чтобы ваш адрес электронной почты разглашался в ответ на запрос общедоступных записей, не отправляйте электронную почту в эту организацию. Вместо этого, свяжитесь с этим офисом по телефону или напишите письмо.
www.FLStandards.org .. | .. # FLStandards. © 2014, Департамент образования Флориды. Все права защищены .. Mathematics.Florida.Standards. (MAFS). Grade 1. Согласно закону Флориды, адреса электронной почты являются общедоступными. Если вы этого не сделаете хотите, чтобы ваш адрес электронной почты был опубликован в ответ на запрос общедоступных записей, не отправляйте электронную почту в эту организацию.Вместо этого, свяжитесь с этим офисом по телефону или напишите письмо.
Samsung hdd
31 декабря 2020 г. · Новости разведения Многократный победитель 3-го класса г-н Мани уходит на пенсию в племенной завод подмастерья во Флориде. Николь Руссо 31 декабря 2020 г. Победитель многократных ставок Мистер Мани будет участвовать в стаде Journeyman Stud в …
Чтобы сохранить электронную книгу Voyages The Florida Standards-Based Mathematics Program (Grade 1+ Anchors), убедитесь, что вы перешли по ссылке под и сохранить документ или иметь доступ к другой информации, которая может быть связана с электронной книгой VOYAGES THE FLORIDA STANDARD-BASED MATHEMATICS PROGRAM (УРОВЕНЬ 1+ ЯКОРЯ).2004. Мягкая обложка. Состояние книги: Новое.
Никогда еще не было более трудного времени для работы преподавателем. Убедитесь, что ваши студенты готовы к карьере, и повысьте их шансы на трудоустройство с помощью пакета WorkKeys. WorkKeys — это система оценок и учебных программ, которые формируют и измеряют основные навыки на рабочем месте, которые могут повлиять на вашу работу и …
Йоруба, имя короля горького листа
Чикагский электрогенератор 66604 частей
1991 nissan 240sx фастбэк
Продажа щенков акиты в лафайетте
Best dark spot diminisher
Ipercent27m a pet in dali Temple eng sub
Как часто нужно проводить ресертификацию баллонов с пропаном. Рабочий лист 1.Биссектриса угла 5a ответ ключ
Nzxt cam rgb не работает
Обновление трансмиссии Ford 2019
Tujhse hai raabta 21 сентября 2019 письменное обновление
Правда о
273 9 to2 нанести 99999 повреждений в мире фнафРазобранный понтонный катер на продажу
Русская православная церковь Флорида
Destiny 2 за пределами света предзаказ ps4
Сертификация не может быть обработана безработица 3
игроков на обмен в madden 20 fantasy draft
Wgu test bank
Учащиеся и студенты могут просматривать и загружать прошлые экзаменационные работы, решения и комментарии маркеров к экзамену по финансовому менеджменту по ссылкам ниже.Highway 301 South Carolina
- Chapter 15 Test Bank Mcgraw Hill файл: единство подключения краткое справочное руководство документ с несколькими вариантами ответов msc химия вступительные вопросы документы решены химия макетные работы 2013 область содержания тест учебные руководства онлайн отдел образования математика конец 2 семестра писчая бумага с подкладкой sbt1 wgu paper cateye cc at100 руководство пользователя …
- Вы можете использовать эти ресурсы, чтобы проверить свои знания и оценить свои и для прохождения этого финансового теста.CFI — официальный глобальный провайдер программы сертификации аналитиков финансового моделирования и оценки (FMVA) ™. Сертификация FMVA® Присоединяйтесь к более чем 350 600 студентам, которые работают в таких компаниях, как Amazon, JP Morgan и Ferrari, и призваны преобразовать …
Liberty University имеет более 600 степеней бакалавра, магистра или доктора. Учитесь в нашем красивом кампусе в центральной Вирджинии или онлайн из любой точки мира!
Изучите Wgu с помощью интеллектуальных веб-карточек и мобильных карточек, созданных лучшими студентами, преподавателями и профессорами.Подготовьтесь к викторине или учитесь в свое удовольствие!
24 июля 2020 г. · Практический тест медсестры по информатике. Сертификационный экзамен Совета медсестер по информатике — это возможность для медицинских работников продемонстрировать компетентность, знания и навыки начального уровня в области информатики медсестер.
Учебные пособия CliffsNotes написаны настоящими учителями и профессорами, поэтому независимо от того, что вы изучаете, CliffsNotes может облегчить вашу домашнюю головную боль и помочь вам получить высокие баллы на экзаменах.
Вопросы для объективной оценки Wgu Asc1 Для тех из вас, кто записался в WGU, кто еще не прошел INC1, позвольте мне примерно объяснить, что это такое: физика, ядерная физика, химия, генетика, науки о Земле, биология, эволюция, экосистемы и астрономия все в одном гигантском научном курсе.
Гленн Миллер в нотах настроения
12 марта 2018 · Худшая часть WGU — непоследовательность. Мало того, что WGU постоянно что-то меняет, но и ваш опыт в значительной степени контролируется вашим наставником-студентом, и каждый из них отличается своим соблюдением и пониманием «правил». Например, многие люди настоятельно рекомендуют открыть полевой курс (C229) как можно скорее и …
30 августа, 2017 · Управлять вашей технологией в онлайн-среде стало еще проще с новой «WGU Systems Check».Это новый инструмент самообслуживания, доступный студентам WGU, который дополняет миссию WGU — позволяет повысить качество и расширить доступ к образовательным возможностям студентов, предоставляя средства для беспрепятственного и легкого управления техническими требованиями в процессе обучения и обучения. ..
3 марта 2016 г. · The LA Times опубликовала статью о том, как онлайн-университеты, такие как WGU, используют передовые технологии для предотвращения мошенничества при онлайн-тестах, а Night Owls из WGU в итоге хорошо поговорили на странице WGU в Facebook о том, что это как прохождение онлайн-экзамена.
Популярные книги. Биология Мэри Энн Кларк, Чон Чой, Мэтью Дуглас. Колледж физики Раймонд А. Сервей, Крис Вуйль. Существенная среда: наука за рассказами Джей Х. Уитготт, Мэтью Лапосата. Все аргументы в пользу обновления ГНД 2016 г. Университет Андреа А. Лансфорд, Университет Джона Дж. Рушкевича. Медсестринский хирург Льюиса Дайан Браун, Хелен Эдвардс, Лесли Ситон, Томас …
Учащиеся и студенты могут просматривать и загружать прошлые экзаменационные работы, решения и комментарии маркеров к экзамену по финансовому менеджменту по ссылкам ниже.
Советы и предложения о том, как сдать Конституцию и правительство Соединенных Штатов, а также математику для преподавателей начальной школы 1 в Университете Западных губернаторов! Любой, кто … Тысячи вопросов для подготовки к экзаменам с подробными видеообоснованиями. Преподаватель №1 на Youtube. Инструкция от преподавателя №1 на Youtube и других хостов, которых вы знаете, любите и доверяете.
Сейчас поворотный момент для рабочего места и персонала, поскольку критические проблемы, влияющие на общество, влияют на работу. Общество управления человеческими ресурсами (SHRM) — крупнейшая в мире ассоциация по управлению персоналом…
Ключевые вещи, которые нужно знать: Практика по мере обучения: Самотестирование: На вашем тесте: Простой тест: Средний Тест: Жесткий тест: Быстрое обучение
Киллин Craigslist бесплатные материалы
Dutchsinse 7 5 19
Управление вашим Технологии в онлайн-среде еще проще с новой «Системой проверки WGU». Это новый инструмент самообслуживания, доступный студентам WGU, который дополняет миссию WGU — позволяет повысить качество и расширить доступ к образовательным возможностям студентов, предоставляя средства для беспрепятственного и легкого управления техническими требованиями в процессе обучения и…
Банк тестов по принципам микроэкономики, 5-е издание … Гранд-Каньон JUS 510 Полный курс — НОВИНКА; … Разработка линии обслуживания WGU (AMT2) — Complete Cou …
Test Bank for The Challenge of Democracy, 12th Edition Этот элемент НЕ является учебником, это набор тестов или руководство по решению, этот элемент является тестовым Банк вызова демократии, 12-е издание.
Самотестирование издателя с множественным выбором. Практический экзамен для издателей. Это документ Microsoft Word, который необходимо загрузить на свой компьютер.Глава Экзамен. 3. Проектирование систем: калькуляция заказов. Верно / Неверно Тест на основе Java; Самопроверка издателя «Множественный выбор». Практический экзамен для издателей. Это документ Microsoft Word, и его необходимо загрузить на …
Клавиатуры Pubg
13 июня 2015 г. · Минусы. Университет построен на оценке студентов. Здесь срезаются углы, и это ставит учеников в невыгодное положение. В политике WGU и информации о студентах говорится, что любой ученик, получивший оценку «Успешно», означает, что ученик продемонстрировал компетентность на уровне «В» или выше.
7. Пройдя несколько практических тестов, Брайан улучшил результаты своего теста GRE на 30%. Учитывая, что в первый раз, когда он проходил тест, Брайан правильно ответил на 150 вопросов, сколько правильных ответов он ответил во втором тесте? а. 105 г. 120 с. 180 дн. 195. 8. Число увеличивается на 2, а затем умножается на 3. В результате получается 24.
Идеальная крышка для банки с шариком Найдите напряжение между a и b
декали Roblox comLeupold 3 9×40
Сканирование иллюстраций на скрепках Каталог предприятий Threshold
| Randy adams vsim post quizlet Подтвержденный ssn paypal | Eclipse dobermans | Dollar7ef code | Sqlcmd_ error_ 912 912 драйвер 912 для сервера Microsoft 922 912 для sqlcmd_ error_ 912 922 драйвер 912 для сервера Microsoft 922 922 922 | -1819 (широкий федеральный закон) Штаты не могут облагать налогом федеральный (национальный) банк — Гамильтон сказал: «Право облагать налогом — это право уничтожать», — заявил Верховный суд, хотя федеральные банки НЕ были перечислены в Конституции США в разделе «Перечисленные полномочия». , ‘они были частью’ необходимого и правильного предложения (или эластичного предложения).Учебное пособие по оценке готовности Wgu Файл: основы менеджмента 9-е издание studio4 leed ap Учебное пособие по математической грамотности экзамен 1 июня 2013 г. yamaha xt600 1983 г. 2003 г. скачать руководство по ремонту на заводе в pdf-формате руководство по маршрутизации в Калифорнии, географическое положение после | |||
| Обнаружена служба Citrix для настольных ПК что сеанс пользователя завершился Индикатор автоматической линии тренда mt4 | 5 3 практических полиномиальных функции ответы форма g | 454 толщина прокладки головки | Как настроить звездочку для отправки sms | ||||
| 3 июня 2019 г. · Не бойтесь экзаменационных вопросов по анатомии и физиологии.Используйте наши бесплатные практические тестовые вопросы по анатомии и физиологии, чтобы убедиться, что вы готовы. Регистрация не требуется! Wiley CIA Test Bank — это продукт на основе браузера, оптимизированный для использования на настольных компьютерах и планшетах. Мы настоятельно рекомендуем использовать в качестве браузера последнюю версию Chrome или Firefox. К нему также можно получить доступ через мобильное приложение. | |||||||
| Отключить современные окна сна 10 Колеса Trd 16 | Bookzz бесплатно | Предохранитель блока управления Integra продолжает перегорать | 496 номер ангела | ||||
| 16 декабря 2020 г. · Университет основан в 1850 году. of Utah — ведущее высшее учебное заведение штата Юта, предлагающее более 100 программ бакалавриата и более 90 программ магистратуры для более чем 30 000 студентов. | |||||||
| Aprilaire 5000 деталей электронного воздухоочистителя Определите величину ускорения блока 2, выразите свои ответы в единицах m1 + m2 g и f | Папирус с подменой x самоубийственный ридер | Джунун: актерский состав | Ati виртуальная симуляция | ||||
| Извините, я не знаю вопрос о тестовом банке, который вы задали, но это, вероятно, был самый сложный тест, который я прошел через магистерскую программу в области здравоохранения.Я напомнил только один или два похожих вопроса к предварительному тесту, иначе фактический тест казался совершенно другим, это было именно для этого класса, так что это отбросило меня от некоторых.-1819 (широкий федеральный закон) Штаты не могли обложить налогом Федеральный (национальный) банк — Гамильтон сказал: «Право налогообложения — это власть разрушать», — заявил Верховный суд, хотя федеральные банки НЕ были перечислены в Конституции США в разделе «Перечисленные полномочия», они были частью «необходимой и надлежащей статьи» ( или эластичная оговорка). | |||||||
| Треугольник заводской пожарный quizlet 2-цилиндровый дизельный двигатель Deutz с воздушным охлаждением | Bape Bearbrick 1000 | Обрушение плотины в Китае | Fseconomy псевдонимы самолетов | ||||
| Привет | 9 декабря 2015 г. , Просто хотел дать свои советы по прохождению класса статистики WGU.Я только что сдал OA и начал урок на прошлой неделе. Я ранее пробовал статистику, когда посещал UTA онлайн, но получил D. У меня есть еще одно задание, которое нужно пересмотреть в Biochem, и это будет мой третий завершенный урок за 3 недели. Путь …|||||||
Фон ластик Hfa + каменистый ручей
| Недостатки информационно-коммуникационных технологий Сгоревшие пары пропана вредны | Гольф колодец 9122 Запасное колесо 9123 D | D5600 external flash Сервисы Google Play для ar несовместимы с моим устройством | ||
| Тестовые ответы Wgu Ответы на тесты Wgu Когда кому-то нужно пойти в книжные магазины, ищите основание по магазинам, полка за полкой, это принципиально проблематично.Основы исследования. Тестирование стратегий и заметок. Стремитесь к идеальным 90? Начните подготовку к академическому экзамену PTE с лучших пробных онлайн-тестов и получите настоящий тестовый опыт. | ||||
| Moto xt1686 imei 0 Живой бесплатный фильм | Дом на колесах Ford ranger | Фары ближнего света очень тусклые 3 | Как обновить ldplayer | |
| Масляный фильтр Motorcraft против wix Отличительное имя объекта | 2001 f150 abs module | Какие башни используют в прямом разговоре Mvis выкуп microsoft | Психология зависимого поведения pdf 12 | |
| Ark Ferized bronto egg id Сброс несъемного аккумулятора Asus | Модернизация автоматической коробки передач Frs | Лезвия Woodmizer lt30 6 | шрифты Tecate | |
| 2 | 33 | |||
Yamaha pro v 115 | Going ballistic bullets Razor ecosmart hack | Замена направляющих рамы Unibody | ||
| Кандидаты от институциональной структуры также должны продемонстрировать знания Федеральной резервной системы. банк и инструменты денежно-кредитной политики, которые он использует для стабилизации экономических колебаний и содействия долгосрочному экономическому росту, а также инструменты налогово-бюджетной политики и их влияние на доход, занятость, уровень цен, дефицит и процентную ставку.Они включены в полный набор вопросов практического теста Security + и разделены на четыре набора примерно по десять вопросов в каждом. Смотрите демо здесь. Дополнительные вопросы, связанные с производительностью, включены как часть бесплатного онлайн-контента, который бесплатно доступен всем, кто приобретает CompTIA Security + Get Certified Get Ahead: SY0-501 … | ||||
Как скрыть телевизионные кабелиJ1850 vpw arduino
| Devskiller javascript test ответы Gtx 1080, разгон напряжения | |||
| Hcf of 16 24 48 Тара Уоллес | Titan RTX 312 Coast Way Sile 9203 9203 Сборка стояночного тормоза F350 | ||
| Учебные пособия CliffsNotes написаны настоящими учителями и профессорами, поэтому независимо от того, что вы изучаете, CliffsNotes может облегчить вашу домашнюю головную боль и помочь вам получить высокие результаты на экзаменах. | |||
Номер Slydial Потные теги игроков xbox не приняты
| Вопрос, связанный с измерением 2-х нитный одномодовый оптоволоконный кабель | |||
| Карта разрушения плотины Мичигана 2 | Факты о биосфере | ||
JMIR Medical Informatics — Встраивание слов для французского естественного языка в здравоохранении
: сравнительное исследованиеВведение
Контекст
Использование клинически полученных данных из электронных медицинских карт (EHR) и других клинических информационных систем может значительно облегчить клинические исследования, а также оптимизировать группы по диагностике или другие инициативы.Основной подход к предоставлению таких данных состоит в том, чтобы объединить их из разных источников в объединенное хранилище данных о здоровье (HDW), содержащее, таким образом, различные виды документов на естественном языке, такие как рецепты, письма, отчеты о хирургических операциях, — все написанные повседневным языком ошибки, сокращения, короткие и неполные предложения).
Распознавание клинических именованных сущностей (NER) — это критическая задача обработки естественного языка (NLP) для извлечения концепций из именованных сущностей, содержащихся в клинических и медицинских документах (включая выписки).Хранилище семантических данных о здоровье (SHDW) было разработано отделом биомедицинской информатики Университетской больницы Руана (RUH), Нормандия, Франция. Он состоит из 3 независимых уровней, основанных на архитектуре NoSQL:
- Сервер межъязыковой терминологии, HeTOP, который содержит 75 терминологий и онтологий на 32 языках []
- Семантический аннотатор, основанный на методах пакета слов NLP. (ECMT) []
- Семантическая многоязычная поисковая машина []
Чтобы улучшить семантический аннотатор, можно внедрить методы глубокого обучения в уже существующий.Для этого необходимо разработать новое текстовое представление, которое сохраняет наибольшее семантическое сходство, существующее между словами, так, чтобы оно соответствовало входным данным алгоритмов нейронных сетей (встраивание текста).
Вложение слов
В НЛП поиск текстового представления, сохраняющего близость смысла, всегда был спорным вопросом. Действительно, выбранное представление должно сохранять семантическое сходство между разными словами из корпуса текстов, чтобы методы индексации позволяли выводить правильную аннотацию.Таким образом, представление уникального токена должно демонстрировать близость с другими связанными концепциями значения (синонимами, гипонимами, когипонимами и другими связанными токенами), как показано в цитате «Вы должны знать слово по компании, которую он держит» [] , теперь известная как гипотеза распределения .
В 60-е годы в системе механического анализа и поиска текстовой информации появилась модель векторного пространства (VSM), которая привела к идее векторного представления слов [,].При таком подходе векторы слов были разреженными (кодирование слова представляло собой вектор размером n , n , представляющий размер словаря). Фактически, компактное и точное представление слов может принести несколько преимуществ. Сначала идет вычислительный аспект. Компьютеры намного лучше выполняют операции с низкоразмерными объектами. Затем это позволяет рассчитать вероятность того, что одно понятие окажется рядом с другим. Более того, размеры векторов, созданные для представления слова, можно использовать для размещения этого слова в пространстве и, таким образом, сравнения расстояний с другими лексемами.Современные методы неконтролируемого встраивания предоставляют плотную и низкоразмерную информацию о слове либо с помощью методов, основанных на подсчете, либо на основе прогнозирования []. Были разработаны различные реализации методов отображения слов в VSM.
Word2Vec
Подход Word2Vec был первым современным внедрением, выпущенным в 2013 году []. Миколов и др. Реализовали 2 вида архитектур: непрерывный пакет слов (CBOW) и skip-gram (SG).
Архитектура CBOW учится предсказывать целевое слово W , используя его контекст C .Эта модель аналогична нейронной сети прямого распространения, предложенной ранее [,]. Однако смещение, вносимое нелинейным слоем, было устранено с помощью общего проекционного слоя. Входной слой принимает однократное кодирование в качестве входных данных X i (предложение кодируется как очень полый вектор. Он состоит из 0 или 1, в зависимости от слов, найденных в этом предложении, и становится X ‘ i при прохождении функции активации). С корпусом, состоящим из V, различных слов и выбранным размером входного слоя N , скрытым представлением этого корпуса будет матрица V × N , где каждая строка представляет слово W v с помощью вектор размерности N .После прохождения функции линейной активации скрытого слоя выход Y i может быть вычислен с использованием функции softmax для каждого слова W V , как описано в уравнении ниже [].
Архитектура SG использует данное слово для предсказания своего контекста, в отличие от архитектуры CBOW. Таким образом, весь корпус V будет преобразован во множество пар target || контекст ( т.е. вход || выход или x i || y i сети) и функция оптимизации стохастического градиентного спуска будет использоваться в этом наборе обучающих данных с мини-пакетом синтаксический анализ [].
Таким образом, скрытая матрица и матрица выходных весов будут иметь форму V × N , где N снова является количеством измерений для векторов слов. Чтобы уменьшить вычисление такого количества данных (при обычном обучении все веса сети должны обновляться для каждого прохода через пример. Количество изменений зависит от размера контекстных окон), авторы принес несколько новых идей. Во-первых, пары слов, всегда встречающиеся вместе, рассматриваются как один токен для обеих архитектур ( New York гораздо более значим, чем комбинация New и York ).Затем подвыборка частых слов позволяет модели повторно инициализировать вектор слов, уменьшая чрезмерное обновление некоторых общих слов. Наконец, отрицательная подвыборка заставляет модель обновлять только часть контекста для каждой цели [].
GloVe
Эта модель вложения выпущена Стэнфордским университетом []. Подобно Word2Vec, GloVe может вставлять слова как математические векторы. Однако он различается по методу, используемому для определения сходства между словами, поскольку GloVe — это метод, основанный на подсчете.Идея заключалась в том, чтобы построить огромную матрицу совпадения между словами, найденными в обучающем корпусе формы V × C , где V — словарь корпуса, а C — примеры контекста. Вероятность P ( V W1 || V W2 ) слова V W1 , находящегося рядом с другим V W2 , будет увеличиваться во время обучения и заполнять со- матрица вхождений.Эта гигантская матрица затем факторизуется с помощью функции журнала, эта идея исходит из модели скрытого семантического анализа [].
FastText
Это новая модель, выпущенная в 2017 году, в основе которой лежит новая идея []. Хотя и Word2Vec, и GloVe предполагали, что слово может быть эффективно и напрямую встроено как вектор, Бояновски и др. [] Считают, что слово могло быть результатом всей векторной декомпозиции этого слова (модель подслова). Каждое слово V W , где V является словарем, может быть разложено на набор векторов из n символов-граммов.Например, слово «лодка» можно рассматривать как (с параметром n-грамм n = 3 , указывающим максимальное количество букв, составляющих подслово). Таким образом, каждое слово внедряется в векторное пространство как сумма всех векторов, составляющих этот токен, включая морфологическую информацию в представление []. Подобно Word2Vec, FastText также поставляется с двумя различными ранее упомянутыми архитектурами (SG и CBOW).
Сопутствующее исследование
За последние несколько лет огромный интерес к встраиванию слов привел к сравнительным исследованиям.Scheepers и др. Сравнили методы встраивания трех слов, но эти модели были обучены на разных и неспецифических наборах данных (Word2Vec на новостных данных, тогда как FastText и GloVe обучены на более академических данных, Wikipedia и Common Crawl, соответственно, такая систематическая ошибка могла быть вызвана такой ошибкой). разница) []. Байронг и др. Также провели сравнение этих трех реализаций, но сосредоточились на сравнении двуязычных автоматических переводов (оценка BLEU []) и без человеческой оценки всех различных моделей.Цель здесь — определить наилучшую способность поддерживать семантические отношения между словами []. Совсем недавно Бим и др. Создали огромные общедоступные вложения слов на основе медицинских данных; однако в этом исследовании не использовался FastText, а использовались только Word2Vec и GloVe. Более того, эталон между методами внедрения был основан на статистических встречах понятий []. Подобным образом Хуанг и др. Глубоко изучили Word2Vec на 3 различных медицинских корпусах, измеряя влияние сосредоточения корпусов на медицину и без оценки семантических отношений [].Наконец, Ван и др. Сравнили влияние обучающего набора встраивания слов на модели, используемые для различных задач НЛП, связанных с медицинскими приложениями, тогда как цель этого исследования — сравнить реализации встраивания, обученные на одном и том же корпусе [].
Более того, многие разные команды или компании выпустили предварительно обученные модели встраивания слов (например, Google, Стэнфордский университет), которые можно использовать для конкретных приложений. Ван и др. Также доказали, что вложения слов, обученные на узкоспециализированном корпусе, не сильно отличаются от тех, которые обучены на общедоступных и общих данных, таких как Википедия [].Однако в клиническом контексте словарный охват этих встраиваний, обученных на академическом корпусе, довольно низок в отношении слов, используемых в профессиональном контексте. Чтобы оценить долю этих неперекрывающихся токенов, из французской базы данных научных статей LiSSa были извлечены выдержки из 1 250 000 статей, которые сравнивались с необработанными данными о состоянии здоровья из SHDW []. Эти медицинские документы содержат в общей сложности 180 362 939 слов, представляющих 355 597 уникальных токенов, а выдержки из базы данных LiSSa состоят из 61 119 695 слов, представляющих 380 879 уникальных токенов.Среди 355 597 уникальных токенов, записанных в документах SHDW, 26,11% (92 856/355 597) не были обнаружены в отрывках из корпуса LiSSa (в основном представляющих собой орфографические ошибки, сокращения или географические местоположения). Таким образом, более четверти словарного запаса, используемого в профессиональном контексте, невозможно лучше внедрить с помощью корпуса академической предварительной подготовки. Таким образом, часто требуется местное обучение по конкретным данным, особенно с языками, отличными от английского, где доступны менее предварительно обученные модели встраивания.
Вклад
Сравнения встраивания слов, таким образом, ранее изучались, но, насколько нам известно, ни одно из них не сравнивало возможности 5 наиболее часто используемых реализаций неконтролируемого встраивания, обученных на медицинском наборе данных, созданном в профессиональном контексте на французском языке. корпуса академических текстов. Более того, при сравнении моделей, обученных на разных наборах данных, может возникнуть смещение.
Таким образом, цель здесь — сравнить 5 различных методов (Word2Vec SG и CBOW, GloVe, FastText SG и CBOW) и оценить, какая из этих моделей дает наиболее точное текстовое представление.Они будут ранжироваться на основе их способности сохранять семантические отношения между словами, найденными в обучающем корпусе. Таким образом, мы расширили соответствующее исследование, (1) сравнив самые последние и использованные методы встраивания по их способности сохранять семантическое сходство между словами, (2) устранив предвзятость, вызванную использованием другого корпуса для обучения сравниваемых методов встраивания, и (3) использование этих алгоритмов встраивания в сложный корпус вместо академических текстов.
Это представление затем будет использоваться в качестве входных данных для моделей глубокого обучения, построенных для улучшения фазы аннотирования, фактически выполняемой ECMT в SHDW.Эта фаза NER станет первым шагом на пути к извлечению многоязычных и мультитерминологических концепций. Более того, построенные модели будут сначала доступны для сообщества, работающего над медицинскими документами на французском языке, через общедоступный интерфейс.
Методы
Корпус
Корпус, использованный в этом исследовании, состоит из части медицинских документов, хранящихся в SHDW RUH, Франция. Все эти документы на французском языке. Они также довольно разнородны по своему типу — отчеты о выписках, отчеты об операциях или процедурах, рецепты на лекарства и письма от терапевта.Все эти документы написаны медицинским персоналом в RUH и, следовательно, содержат множество опечаток, опечаток или сокращений. Эти неструктурированные текстовые файлы также были очищены путем удаления общего заголовка (содержащего адрес RUH и номера телефонов).
Деидентификация документов
Эти документы были затем деидентифицированы, чтобы защитить каждую личность каждого пациента или врача от RUH. Каждое имя и фамилия, хранящиеся в основных базах данных RUH, были заменены неинформативными токенами, такими как
Предварительная обработка
Сначала возникает вопрос о форме входных данных. Должен ли он состоять из блоков предложений (данные состоят из списка токенизированных предложений) или подразделяться по документам (список токенизированных документов)? Ответ на этот вопрос зависит от того, для чего будет использоваться модель.В нашем случае важен контекст каждого документа (но не контекст каждого предложения, что является хорошим представлением для документов, имеющих дело со многими предметами). Следовательно, входные данные будут основаны на разделении документа.
Затем данные были уменьшены (дополнительная информация о сохранении сходства семантики слов за счет различий между верхним и нижним регистром для этого исследования не была внесена), пунктуация была удалена, а числовые значения были заменены мета-токеном < номер> .Мы решили не удалять стоп-слова из-за их незначительного влияния на контекст. В самом деле, их множественные появления во многих различных контекстах просто создали бы кластер стоп-слов в середине VSM.
Обучение
Модели реализованы благодаря библиотеке Gensim Python []. Они прошли обучение на сервере под управлением 4 XEON E7-8890 v3 и 1To оперативной памяти, расположенной на RUH. Мы основывали настройку гиперпараметров моделей на литературе [] и на собственном опыте.Целью здесь было сравнить реализацию встраивания слов; поэтому мы решили сохранить эквивалентные параметры для каждой модели. Выбранные значения перечислены в.
Таблица 1. Значения гиперпараметров, используемые для обучения моделей встраивания 5 слов.| Параметр, применяемый к модели | Значение | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Эпохи | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Word2Vec / FastText | Минимальное количество токенов | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Все 3 модели | 20 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Размер контекстного окна | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Все 3 модели | 7 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9000 | 2 Скорость обучения модели2.5×10 -2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Размер встраивания | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Все 3 модели | 80 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Скорость альфа | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Все 317 922 912 912 912 912 912 912 912 912 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Word2Vec / FastText | 12 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Субдискретизация | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GloVe | 1e -6 | 1e -6 9322 912 который может представить неакадемический текст в математической форме, которая сохраняет контекстную информацию о словах, несмотря на предвзятость, вызванную низким качеством используемого языка.Для этого были определены различные метрики, сосредоточенные на задачах сходства слов. Положительные отношения оценивались с помощью задачи на косинусное сходство, а отрицательные — с помощью задачи на нечетную единицу. Операции на основе аналогий и человеческая оценка позволяют нам оценить, может ли данная модель сохранить глубокий смысл лексемы (антонимы, синонимы, гипонимы и гиперонимы).Косинусное сходствоСходство между вложенными парами концепций оценивалось путем вычисления косинусного сходства.Он также использовался для оценки того, связаны ли эти 2 концепции или нет. Косинусное сходство (cos) между векторами слов W1 и W2 указывает на ортогональные векторы, когда они близки к 0, и очень похожие векторы, когда они близки к 1. Оно определяется как: Можно определить набор проверки, состоящий из пар терминов, которые должны использоваться в аналогичном контексте в наших документах (например, flu и virus ). Затем первый токен от каждой пары отправляется в каждую модель, и извлекаются 10 самых близких векторов относительно косинусного сходства.Второе слово должно быть извлечено из этих 10 ближайших векторов, чтобы считаться успешным. Затем общий процент ( p ) успеха вычисляется относительно общего количества пар слов, причем N — это количество раз, когда второй член был найден в 10 самых близких векторах первого с: Для создания набора данных использовались 2 хорошо известных набора проверки, UMNSRS-подобие и UMNSRS-Relatedness, содержащие соответственно 566 и 588 вручную оцененных пар концепций, которые, как известно, часто встречаются вместе, [].Однако, поскольку наш корпус был на французском языке, для перевода этих двух наборов использовалась переведенная и выровненная версия терминологии MeSH, хранящаяся в HeTOP []. Результат предоставил 308 пар для UMNSRS-подобия и 317 пар для UMNSRS-Relatedness, остальные концепции не были непосредственно обнаружены в MeSH. Сходство «нечетное», «одно-выходное»Задача «Нечетное, одно-выходное» пытается измерить способность модели отслеживать отрицательное семантическое сходство слов, давая модели 3 разных слова.Среди них 2 известны как связанные, а не третий. Затем модель должна вывести вектор слов, который не кластеризуется с двумя другими (например, выходной автомобиль, когда на входе автомобиль, баскетбол, теннис ) []. Чтобы создать такой корпус валидации, был извлечен каждый термин из подзаголовка «Медицинский подзаголовок» (MeSH), который встречается в корпусе более 1000 раз. Результатом стал список из 516 терминов MeSH, которые были вручную кластеризованы в 53 пары связанных концепций MeSH по мнению 2 разных врачей (MD).Затем 53 слова, встречающиеся в корпусе более 1000 раз, были случайным образом выбраны для использования в качестве нечетных терминов, по одному для каждой пары терминов MeSH. Матрица косинусного расстояния между 3 токенами была рассчитана для каждого элемента нечетного списка и для каждой модели. Цель модели — вывести косинусное расстояние между каждым из двух связанных членов и нечетным ближе к 0 по сравнению с расстоянием между этими двумя связанными членами, которое должно быть ближе к 1 (что указывает на большее количество похожих векторов). Затем рассчитывается процент успеха p. Оценка на людяхОфициальная оценка 5 методов была проведена резидентом общественного здравоохранения (CM) и доктором медицины (SJD). Список из 112 терминов был извлечен из терминологии MeSH. По крайней мере, 3 концепции были извлечены из каждой ветви терминологии MeSH (независимо от характеристик публикации ветви, V). Все эти 112 членов были отправлены в каждую модель, и из каждой модели были извлечены 5 самых близких векторов косинусного расстояния. Перекрывающиеся векторы между моделями были сгруппированы, чтобы избежать многократной оценки одного и того же ответа, а общий список был рандомизирован, чтобы избежать утомления комментатора.Затем CM и SJD вслепую оценили релевантность каждого вектора по сравнению с отправленным токеном. Эти цитаты были оценены на предмет релевантности по трехуровневой шкале, используемой в других стандартных наборах тестов информационного поиска: плохая (0), частичная (1) или полная релевантность (2). Операции на основе аналогийСтатья Миколова, представляющая Word2Vec, показала, что возможны математические операции над векторами, такие как сложение или вычитание, такие как знаменитое ( король – мужчина ) + женщина – королева .Такая задача помогает проверить семантическую аналогию между терминами. С помощью операции Миколова можно утверждать, что король и мужчина имеют те же свойства отношений, что и королева и женщина . Чтобы проверить сохранение этих свойств каждой моделью, в соответствии со стилем Миколова были определены несколько математических операций, охватывающих широкий круг возможных предметов, обнаруженных в EHR (отделения больниц, человеческие ткани, биология и лекарства) ([ Term 1 — Term 2 ] + Срок 3 ~ Срок 4) ).Затем операция была выполнена с использованием векторов Term 1 , Term 2 и Term 3 , извлеченных из каждой модели. Результирующий вектор сравнивался с вектором Term 4 , операция считалась правильной, если этот вектор Term 4 оказался ближайшим в отношении косинусного расстояния с результирующей операцией, что указывает на семантическое сходство между Term 3 и Term 4 , аналогично тому, что между Term 1 и Term 2 . Кластеры словВ VSM слова сгруппированы по семантическому сходству, но контекст действительно сильно влияет на это расположение. Векторные размеры каждой модели были уменьшены и спроецированы на 2 измерения с помощью алгоритма t-SNE. Затем в проекции вручную производился поиск кластеров логических слов. Этот шаг не входил в общую итоговую оценку, но позволял быстро оценить качество представления слов. Идем дальше: улучшение моделиЧтобы проверить, повлияло ли предварительное обучение модели на результат или нет, новая версия лучшей модели в отношении задач, описанных выше, была обучена дважды.Во-первых, французские бумажные выдержки из корпуса LiSSa (всего 1 250 000) были использованы для предварительного обучения модели. Затем полученное в результате встраивание было обучено второй раз на документах из RUH без изменения каких-либо параметров. Все автоматические тесты были выполнены для этой модели во второй раз, чтобы оценить, улучшили ли добавленные академические данные качество модели с точки зрения нашей оценки. РезультатыКорпусВсего было деидентифицировано и предварительно обработано 641 279 документов из RUH.Что касается словарного запаса, тексты были разделены на 180 362 939 слов, что составляет 355 597 уникальных токенов. Однако с этим числом можно подумать: 170 433 слова встречаются только один раз во всем корпусе (в основном это орфографические ошибки, а также географические местоположения или биологические объекты, такие как гены и белки). В общей сложности 50 066 различных слов были обнаружены в корпусе более 20 раз, таким образом, присутствуя в моделях (минимальный параметр счета установлен на 20). В среднем каждый документ содержит 281.26 слов ( SD 207,42). 10 самых распространенных слов перечислены в. Таблица 2. 10 самых распространенных слов нашего корпуса. Обратите внимание, что Руан — это город, откуда берутся данные обучения.
Эти документы были разложены с использованием алгоритма, основанного на частотах и обратных документах (TF-IDF), в результате чего была получена матрица частот. Каждая строка, представляющая статью, использовалась для кластеризации этих документов с помощью алгоритма kMeans (количество классов K = 5).Для визуализации их распределения в двух измерениях использовался алгоритм t-SNE () []. Эти основные классы были хорошо разделены, поэтому самого словаря, содержащегося в документах из HDW, было достаточно для кластеризации каждого типа текста. Однако отчеты о выписках, операциях или процедурах были немного более неоднозначными из-за слов, используемых в таких контекстах (короткие предложения, акронимы и сокращения, а также высокотехничная лексика). Что касается рецептов на лекарства и писем коллеге или терапевта, они представляют собой более конкретную лексику (лекарства и химические вещества и текущий / официальный язык, соответственно), включая более определенные кластеры для этих 2 групп. ОбучениеЧто касается времени обучения, то модели были очень разными. GloVe был самым быстрым алгоритмом для обучения за 18 минут для обработки всего корпуса. Вторую позицию занял Word2Vec с 34 мин и 3 часами 02 мин (архитектуры CBOW и SG соответственно). Наконец, FastText был самым медленным алгоритмом с временем обучения 25 часов 58 минут с SG и 26 часов 17 минут с CBOW (). Таблица 3. Время обучения алгоритмов (мин).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||